
Published Date : November 27, 2016
Categories : OB/Gyn
I recently came across this quote from an article in The American Journal of Surgery:
Then gynecologists became enthused over this new surgery and departed from their vaginal technique in order to combine their indicated pelvic work with these new operative wrinkles. In consequence, vaginal surgery became neglected and recently one could find busy clinics where not a single vaginal hysterectomy had ever been performed either by the present staff or by their predecessors. … Since the vaginal approach to pelvic disease is associated with less mortality, a small morbidity rate and a much more rapid convalescence, it is high time that present day gynecologists learned to appreciate the value of vaginal hysterectomy, acquire its technique, and extended its use.
I couldn’t have said this better myself. Reflecting back over the last twenty years, we have seen the time-honored and premier approach of vaginal hysterectomy slowly and painfully displaced by “new wrinkles” that have gained gynecologists’ enthusiasm. First, it was laparoscopy. This once novel approach appealed to the gynecologist’s desire to use the latest and greatest technology and toys – even if it came at a cost to women. At first, most laparoscopic hysterectomies were done as supra-cervical cases, as gynecologists slowly crawled up the learning curve. Leaving the cervix behind exposed women to risks, like cervical dysplasia and cancer, future prolapse, continued bleeding, and a possible future need for a trachelectomy. Once the cervix was within more gynecologists’ wheelhouse, a new cost to women arose: a near 10-fold increased risk of vaginal vault prolapse, along with significantly higher rates of bladder injuries, bowel injuries, and ureteric injuries. All the while, laparoscopic hysterectomy still trailed far behind vaginal hysterectomy in terms of cost, length of stay, cosmesis, and patient satisfaction.
Over time, vaginal surgery developed an increasingly-present crutch: laparoscopic-assistance. This tool was usually more a bandaid for declining vaginal skills than a true necessity. Pure vaginal hysterectomies were becoming relegated to surgeons over 50 years of age and to women with significant prolapse.
Soon enough, the next new operative wrinkle was the robot. The robot was supposed to fix many of the problems that the laparoscope had created: e.g., neck strain and back pain for the surgeon – while leading to improved exposure and instrument flexibility, etc. Yet, the only thing that really changed was an increased length of surgery, more and bigger holes on the abdomen, and substantially increased costs. Vaginal surgery, though, continued to fall into neglect and year after year it has become harder and harder to teach the next generation of gynecologists this cornerstone of our speciality due to fewer cases and poorer skills among attending physicians. A recent ACOG survey estimated that not even 1/3 of OB/GYN residents going into fellowship training are able to perform a vaginal hysterectomy independently.
Thus, as the quote above proclaims, today there exists whole clinics where vaginal hysterectomy is a lost art; where it is performed, it is usually woefully under-utilized. But I must confess something to you: the above quotation was written by N. Sproat Heaney in 1940, some 76 years ago! You see, the robot and the laparoscope are not the first inferior tools to come along and threaten the existence of the vaginal hysterectomy. The first threat was the abdominal hysterectomy.
The first modern vaginal hysterectomy was performed by Conrad Langenbeck in 1813 (though vaginal hysterectomies for prolapse date back over 2000 years). It wasn’t until 1843 that Charles Clay did the first abdominal hysterectomy. Vaginal hysterectomy remained preeminent until the 1900s, when Howard Kelly, one of the “Big Four” at Johns Hopkins, decided that huge abdominal incisions were much better and therefore popularized the abdominal approach. Most other gynecologists joined in lock-step. They felt like “real” surgeons with their expansive incisions and two week hospitalizations.
Kelly promised better exposure than the vaginal route, and an opportunity to do other things while there, like appendectomies and the opportunity to work on any other pathology that might be discovered during this exploratory laparotomy. Sound familiar? Kelly and his followers exposed generations of women to unnecessary invasiveness and often unnecessary surgeries for what we now know today were just anatomic deviations. Heaney, in the above quote, gives as an example the surgical correction of Jackson’s membrane and he chides gynecologists who chose to “invade the abdomen for ‘chronic’ appendicitis.”
Well, at least nothing much has changed.
Heaney was courageous for standing up against the fads of his time and putting the health of women first. Might we be ever so valiant.
Published Date : November 27, 2016
Categories : Cognitive Bias, OB/Gyn

Tallinn, Estonia
In ancient times they had no statistics so they had to fall back on lies. – Stephen Leacock
In almost every situation where data can be collected and analyzed, we are faced with comparisons of that data to itself. This is sometimes a useful technique – but not always. For example, school grades can be used to compare one student to another, identifying the top 10%tile of students as well as the bottom 10%tile of students. This might have meaning; it might be that the top 10%tile deserve scholarships and other opportunities, while the bottom 10%tile deserve remediation. We naturally stigmatize the bottom 10%tile and applaud the top 10%tile. But this can be, in certain situations, wholly artificial.
Is the goal of education to stratify students into percentiles? No. The goal is for students to achieve competency in a curriculum. Not all students will achieve competency in a given curriculum, particularly as the subject matter gets more difficult (achieving competency in kindergarten has little correlation with achieving competency in medical school). But, in any event, the goal should be that students achieve some predefined level of competency. That’s not to say that some students won’t achieve that goal easier than others do, nor do I claim that comparing students to one another is unimportant. We certainly do need to identify those advanced students so that they can attempt more advanced competencies. But my point is that when we compare groups of students to one another, that is a different thing from deciding whether a student is competent. In other words, belonging to a certain percentile, in and of itself, is absolutely meaningless.
A class full of 100 high-achieving students may all one day have great academic success and they may all be competent in their chosen endeavors; nevertheless, one of them still constitutes the bottom 1%tile. Similarly, a class full of 100 poor achieving students, none of whom will ever achieve significant success, still has someone in the top 1%tile. Thus, the sample group being compared to itself matters immensely. We know this already from life experiences. Earning a B grade in an advanced physics class at MIT surely has more merit than an A grade earned in an introductory science course in a community college. But this false comparison, forced on us by what I call the Percentile Fallacy, applies to all sorts of descriptive statistics.

Consider, for example, the 50 best countries in the world as ranked in regards to maternal mortality (or any other metric you might be interested in). The difference between 1st and 50th may be substantially insignificant. In fact, considering error in collecting data (poor reporting, differences in labeling, sampling size, etc.) along with differences in populations (e.g., differences in risk factors among the various populations), there may be no real substantial difference between 1st and 50th place that’s not attributable to chance alone (and therefore just noise in the data). But, yet, some country will always come in 1st place and some country will always come in 50th place.
I won’t spend a lot of time dissecting the problems with maternal mortality reporting around the world, but note above that Estonia is ranked 1st in this report while the US is ranked 47th. Does Estonia really have the most advanced maternity care in the world? No.
Estonia averages about 14,000 births per year (compared to about 4 million in the US). The small sample size of countries like Estonia and Iceland tend to make them look very good (often having just 0 or 1 maternal death in a given year). There are single hospitals in the US that deliver more babies per year than Estonia or Iceland (and I personally have delivered more babies per year than Liechtenstein, Monaco, and San Marino). Women with high risk conditions in Europe tend to travel out of these countries for maternity care, so the sample is diluted of complicated patients. Throughout different countries of the world, wide variation exists about what is considered a maternal death and how these deaths are reported and collected. Is any women with a positive pregnancy test who dies considered a maternal death? No, not ideally. In theory, the pregnancy should contribute to the death. So should a woman who dies of pneumonia or a pulmonary embolism four weeks after delivering a baby be considered a maternal death? These types of decisions are not made uniformly.
In the US, various projects aimed at increasing local identification of pregnancy-related deaths have found both significant under-counting of pregnancy-related deaths and also significant over-counting. We simply don’t know the real rates even with complicated tracking and recording systems. So how well can we expect Slovakia, with fewer obstetric resources than the state of Tennessee, to do with tracking its true maternal mortality rate? Yet Slovakia, according to the data above, has almost one-third the rate of maternal mortality of the United States. The truth is we cannot really use this data for a like-kind comparison. We can use data from 2014 Slovakia to compare it to 2013 Slovakia, but not to 2014 Oregon.
But these insignificant differences are parlayed by special interest groups and policy-makers into a crisis that needs rescuing for those poor, bottom-dwelling, low-percentile countries like the United States. These types of comparative statistical errors are rampant in nearly every aspect of science and public policy. As long as we have 50 states, some state will rank first and some state will rank 50th in every imaginable statistical category; and some politician or special interest group will exploit that 50th place ranking as a reason to change policies or laws, spend more money, and raise the public angst. But some state will always be 50th. Some country will always be near the last, and some student will always be near the bottom percentile.
The “problem” is not the country, state, or student, the problem is what I call the Percentile Fallacy. The percentile fallacy occurs whenever one member of a group is thought to be problematic compared to another member of the group not because they have failed to meet some objective standard but because they have to be on a different part of the bell-shaped curve.
Hospitals are guilty of the percentile fallacy every day. Hospitals collect troves of data comparing themselves to other hospitals. They may all be excellent (or they may all be horrible) but some hospitals will always constitute the “top performers” and others will be basement dwellers. What’s worse, reimbursement for services is moving towards the same erroneous formula, where hospitals and doctors who are in the top percentiles of some metric are rewarded with more money while those in the bottom percentiles are penalized by having money taken away. This is a zero sum game (which is why payers like it) and it doesn’t really identify competency (which should be the real goal). The top percentile performers may be woefully incompetent in some category and have no real incentive to improve, so long as they are just a teeny bit less crappy than everyone else. And in the other extreme, virtually every hospital or provider may be doing a good, competent job, but some will still be penalized because there will always be those bottom percentiles. We need thresholds of good performance, not percentiles.
The percentile fallacy is pervasive in life. It does little to promote actual competency and rather promotes learning how to play the data-collection game well. It rewards those who understand the formula, which often has little basis in true competency. In healthcare, most performance metrics are picked because of ease of access to data that can be computed by some central organization. For example, in obstetrics, a widely proposed “quality metric” may be whether all pregnant women are screened for gestational diabetes during their pregnancies. This test is chosen not because it is important but because it assumed by policy makers that it should be occurring universally and because the data is available (since a charge is submitted by the physician for this service).
Now the competent, evidence-based approach to this issue of screening is to screen first with history and then to perform a chemical screen on high and average risk women (not low risk women). But because this artificial measure of competency is erected, all physicians will start doing the sometimes unnecessary (and sometimes harmful) chemical screens even on low risk women. The bottom-dwelling outliers are not likely to be generally incompetent obstetricians but, rather, ethical, evidence-based providers who couldn’t bring themselves to harm their patients by doing the wrong thing.
Eventually, in such an incentivized system, physicians will all play the game and make sure every patient gets screened (no doubt some will submit charges even if the test didn’t actually get done so that they don’t get financially harmed). They will all learn to play the game. This could be used for good if physicians were incentivized to do something truly essential, but there are few examples of this type of incentivization. So what happens when the top performing physicians all screen 100% of their patients and the bottom performing physicians all screen 99.5% of their patients? Well, there will still be a top quartile and a bottom quartile, and someone will get bonused for no good reason and someone will get penalized for no good reason. This is the percentile fallacy in action.
Put another way, the percentile fallacy leads to harm whenever it is inappropriate to make such comparisons. We shouldn’t be interested in such false comparisons; rather, we should be interested in certain levels of performance or competency.
Here’s another example: Let’s say we instituted a quality measure than stipulated that any obstetrician with a total cesarean delivery rate less than 25% will be financially rewarded. This reward should be available to every single doctor, if they can achieve the standard. This is a competency based approach. The alternative is to use percentiles. If we used the percentile instead, physicians will all aim for the better percentile and work to lower their cesarean delivery rates; this could be good in the short term. But eventually, the best performing docs, having been overtaken or matched by everyone else, will strive for even lower cesarean rates. This would be acceptable incentivization if a cesarean delivery rate of 0% were desirable – but it isn’t, and we don’t know what rate is too low. Eventually, patients will be harmed by physicians not performing appropriate cesareans so as to maintain their prime reimbursement status. In this way, and in thousands of comparable examples, the percentile fallacy is harmful.
I started with an education example, and this is an important misuse of the fallacy. Our goal in education has to be competency. Students should not receive credit for a course or a degree if they cannot perform certain skills and possess certain knowledge and attitudes. We encourage students to game the system with our current system of standardized tests, a pump-and-dump attitude towards knowledge, and little emphasis on critical thinking skills. Thus, the majority of people who have graduated with degrees are incompetent. Don’t believe me? You probably made an A in calculus in college (if you are reading this); care to evaluate some indefinite integrals? I didn’t think so. Of course, that probably wasn’t the goal of your calculus course; but if it wasn’t, then what was? We must clearly define expected goals and competencies, or nothing has meaning. What are the competencies of a good physician? How should we define those (and demand them)? Our system of merits must enforce these competencies, but our current system rewards unethical behavior and patient harm.
Published Date : November 27, 2016
Categories : OB/Gyn

Here are some sample operative notes for obstetrics and gynecology. Feel free to download and modify these for your use. We will add others from time to time, and make corrections or modifications as needed. So far there are examples for:
Published Date : November 22, 2016
Categories : Evidence Based Medicine, OB/Gyn
One of the great limitations of physical exam is that many (if not most providers) don’t do it very well. I have previously recommended the Stanford 25 as an excellent resource to enhance physical exam skills. In the case of clinical breast exam (CBE), the literature has been increasingly unkind to this stalwart of gynecologic practice. The American Cancer Society questions the value of CBE alone to detect worrisome lesions, though it may serve a role in reducing the number of false positives associated with mammography. In 2015, they stopped recommending that CBE be performed at all, which is in line with recommendations from the US Preventative Task Force Service.
Thus, clinical breast exam may be going the way of self-breast exam (SBE). SBE hasn’t been widely recommend in nearly 20 years; it has never been shown to decrease mortality from breast cancer, but it has been associated with an increased number of patient complaints stemming from benign issues – and an increased number of biopsies and interventions to go along with these complaints. From this perspective, SBE (in low risk women) is a net harm: increased interventions and risks with no betterment in outcomes.
Obviously, a major problem with SBE is that it is performed by incompetent examiners. Women may know their own breasts very well, but they are usually ill-prepared for performing the proper techniques and understanding how their breasts change with time of life, pregnancy, weight changes, hormonal status, etc. It is hardly surprising that SBE is net harmful. If we gave people stethoscopes and told them to listen to their own hearts for murmurs, we wouldn’t be surprised if this were also an ineffective strategy. But should cardiologists not listen to hearts?
I am suggesting that CBE may have shown poor utility in clinical studies primary because most providers are not doing the exam correctly. We don’t have studies that control for the methods used for CBE and the effect of appropriately-performed CBE on mortality; we do have evidence that CBE reduces false positive discoveries when used in conjunction with mammography or MRI and we have evidence that CBE may improve patient compliance with mammography. We have evidence that appropriate technique for CBE can greatly increase the sensitivity for smaller lesions. We also know that CBE is useful for symptomatic patients and perhaps for high-risk patients. In order to maximize these benefits, we must be as good as we can be as CBE. Perhaps with more widespread use of good technique, CBE might show promise as a primary screening tool again in average risk women, particularly in the coming era of fewer screening mammograms and later onset of mammography (age 50 and up).
Remember, the goal of mammography is to detect lesions before they are palpable, while the goal of CBE is to detect early, palpable lesions. So studies which compare the efficacy of CBE to mammography will never show that CBE is of value, though it may produce fewer false positives (less over-diagnosis). However, if mammography becomes routine starting at age 50 (as opposed to age 40), then CBE (done well) may show value in detecting small lesions that are not otherwise detected since mammography won’t be routinely used in these populations. CBE is 58.8% sensitive and 93.4% specific for detecting breast cancer; this may not be good compared to mammography but it is excellence compared to no screening at all. While it is true that no current data shows a mortality benefit for CBE, it is also true that no current study shows a mortality benefit for mammography.
Let’s look at four essential skills for a quality clinical breast examination.
1. Cover all of the tissue systematically (use vertical stripes).

The breast is a comma shaped organ with its tail extending upwards into the axilla. All of the breast tissue needs to be systematically palpated. Popular methods for this include circles of increasing size, starting from the nipple and moving outward; wedges radiating to or from the nipple in different radial directions, and vertical stripes (or horizontal stripes, the ‘lawn mower method’). Multiple studies have shown that the vertical stripes method is at least 50% more sensitive than other methods and leads to more consistent coverage of breast tissue. The data is very clear that this the only acceptable method for SBE and CBE.
2. Use the pads of three fingers, one hand at at time.

The most sensitive parts of the fingers are the pads of the digits, not the tips. As in the drawing above, the pads of three fingers should be used for palpation. Many providers will use the tips of the fingers, pushing down in alternating motions (as if typing or playing the piano); this method is essentially worthless to detect small tumors (less than 1 cm). Additionally, using only one hand at time enhances your brain’s ability to process all of this sensory information accurately. While bimanual haptic perception (using both hands) is beneficial for identifying large objects (cylinders, curved objects, horses, etc.), this is not the case for fine touch. There is integration of sensory information from digits which are from the same somatosensory map (for example, the middle three fingers) but not from different maps (for example, the thumb and little finger or fingers from two different hands) for fine touch. So use the pads of the middle three fingers and only use one hand at a time (of course you may need the other hand for positioning of a large breast, but not for simultaneous palpation).
3. Make overlapping circular motions.
The best way to feel a nodule underlying superficial layers of skin and fat is to make circular motions (circumscribing a radius about the size of a dime) with your fingers. This will make skin and fat layers roll over the lump and the lump will stand out. Simple downward compression is far less effective at detecting an underlying mass. Multiples studies have shown that small circular motions greatly enhance palpation technique for breast exam compared to any other method.
4. Use three levels of pressure (compression).
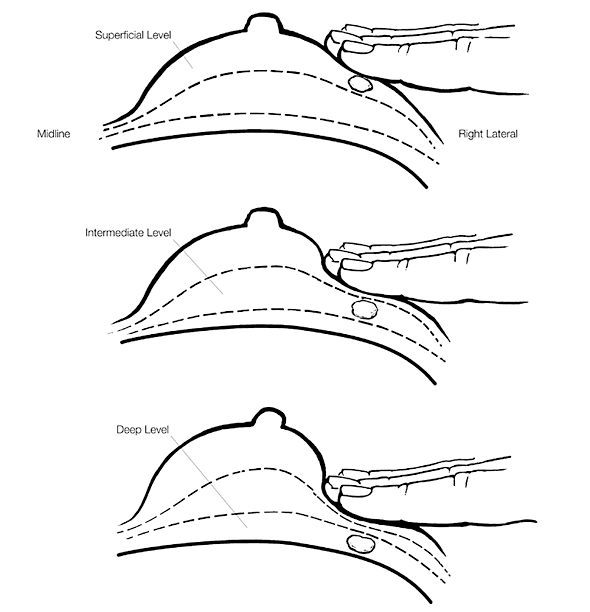
Because tumors may be relatively superficial just under the skin, very deep next to the chest wall, or anywhere in between, then compression of the breast tissue in three specific levels is appropriate for most breasts. A deep tumor may not “roll” under the fingers with light pressure, and a superficial tumor may not “roll” under the fingers with too firm (deep) pressure. Combined with a circular motion, these three levels of palpation can be executed in one successive movement: after placing the three fingers, one rotation with light pressure, then intermediate pressure, then full pressure. Simply move your hand over with about a finger’s breadth of overlap and repeat.
Bonus tips.
Don’t routinely attempt to express fluid from the nipples. This painful maneuver has no clinical utility in asymptomatic women and produces a large number of false positive (most women who have had children can be made to discharge fluid).
Don’t teach your patients to perform self-breast exams or to practice self-breast awareness, unless they are in a high-risk group for breast cancer. These practices have been long abandoned and have been shown to be harmful. If the patient is in a high-risk group, then the four elements described here are essential to educating your patient.
Don’t forget about palpation of axillary and clavicular lymph nodes and inspection for nipple symmetry, etc. These elements of the breast exam are most important for women in whom you suspect a mass or who are otherwise high-risk.
Don’t worry about timing. Studies are mixed about how long it should take to perform an exam, and it clearly will vary considerably based upon breast size and the complexity of what is being palpated. Still, if a whole breast exam takes 20-3o seconds, you probably are not using these techniques.
Bottom line.
These principles are the core of the MammaCare breast examination method and have been shown to greatly enhance the ability of CBE to detect small lumps compared to other methods. A large body of clinical research exists showing the superiority of these combined methods. Only a small percentage of providers utilize these four essential elements, and therefore the efficacy of CBE is greatly diluted. CBE should become more important in the years to come as women more often do not receive mammography until age 40, and hopefully future studies will focus on the utility of CBE with appropriately employed techniques.
Published Date : November 21, 2016
Categories : #FourTips, OB/Gyn
Here’s a new video with four tips to hopefully make vaginal hysterectomy a bit easier. If you haven’t yet, take a look at this post on vaginal hysterectomy.
Published Date : November 15, 2016
Categories : Cognitive Bias

A lot of folks on both ends of the political spectrum were shocked at the results of the recent national election. Virtually every poll and pundit had not only predicted a fairly easy victory for Hillary Clinton but also had predicted that the Democrats would retake the Senate. Neither happened and, in retrospect, neither outcome was even really that close. A lot of analysis has followed about what went wrong in the prediction business. Were the polls that wrong? Are the formulae that are used to predict outcomes that skewed? This has not been the case in the last two presidential elections. The fact that polls have been so accurate in recent elections made the results of the election, in most people’s eyes, all the more unbelievable. Did people lie to the pollsters? Were folks afraid to say that they were planning to vote for Trump? Did they lie to the exit pollers about their votes? Were the pollsters in the bag for Hillary so much so that they made up data or manipulated the system?
The results of the election were counterintuitive to those leaning left and so the fact that it happened is hard to reconcile. The results were also surprising to many of those leaning right, particularly those who had too much faith in the normally reliable polls. What can we learn from this error of polling science and how does it apply to medical science?
As I said above, virtually every pollster was wrong, and those who have too much faith in the science behind polling are the ones who were most shocked about the outcome of the election. As a general rule, an increasing number of people have too much faith in science in general (we call these folks Scientismists). Science has become the new religion for many people – mostly college educated adults, and even more so those with advanced degrees. As with many religions, Scientism comes with false dogma, smugness, self-righteousness, and intolerance. Anyone who disagrees with whatever such a person might consider to be science is dismissed as a close-minded bigot. Facts are facts, they will claim, and simply invoking the word ‘science’ should be enough to end any argument.
But this way of thinking is absurdly immature. Those who believe this way have made the dangerous misstep of separating science from philosophy (see below). You cannot understand what a fact even is (or knowledge in general) without understanding epistemology and ontology which are, and forever will be, fields of philosophy. An interpretation of science in the rigid, dogmatic sense that most scientism bigots espouse is incompatible with any reasonable understanding of epistemology and is shockingly dangerous.
History is full of scientific theories that were once widely believed and evidenced but which today have been replaced by new theories based on better data. Talk of geocentrism, for example, just sounds silly today, along with the four bodily humors in medicine or, perhaps, the hollow earth theory. But not too long ago, these ideas were believed with so much certainty that anyone who might dare to disagree with them did so at his own peril.
Now I am not making the science was wrong argument, which is too often used to support non-sensical ideas like the flat earth or other such woo. True science doesn’t make dogmatic and overly-certain assertions. Scientific ‘knowledge’ is usually transitory and true scientists should constantly be seeking to disprove what they believe. Science is not wrong, but, rather, people have been wrong and used the name of science to justify their false beliefs (and in many cases persecute others). Invoking science as an absolute authority is wrong (and dangerous). I would remind you that physicians who believed in the four bodily humors and/or denied the germ theory of disease in the 19th century felt just as certain about their beliefs as you might about, say, genetics. They were making their best guess based on available data, and so do we today; but we should be open to other theories and new data. Don’t be so dogmatic and cocksure.
So the first lesson: If you truly understood science, then you would believe in it far less than you likely do. Facts are usually not facts (they are mostly opinions). It takes a keen sense of philosophy to keep science in its place. But be leery of those who start sentences with words like, “Science has proven…” or “Studies show…”
How does this apply to the polls? Polls are scientific (as much as anything is) but that doesn’t make them free of bias or other errors. The wide variation in polls and the vastly different interpretation of polls is evidence enough that the science of polling is far from exact. More than random error accounts for these differences; there are fundamental disagreements about how to conduct and analyze polls and subjective assumptions about the electorate that vary from one pollster to the next.
A voter poll is not a sample of 1000 average people that reports voter preference for a candidate (say 520 votes for Candidate A versus 480 for Candidate B). We don’t know what the average person is nor can we quantify the average voter. So a pollster collects information about the characteristics of the person being polled (gender, ethnicity, voting history, party affiliation, etc.) and then asks who that person is likely to vote for in the election. The poll might actually record that 700 people plan to vote for Candidate B while 300 plan to vote for Candidate A, but this raw data is normalized according to the categories that the pollster assumes represent the group of likely voters. This raw data is transmuted (and it should be) so that the reported result might be 480 for Candidate A and 520 for Candidate B. But this important process of correcting for over-sampling and under-sampling of various demographics is a key area where bias can have an effect. Assumptions must be made and the pollster’s biases invariably affect these assumptions.
Such is the case for most scientific studies. If you already assume that caffeine causes birth defects, you are more likely to interpret data in a way that comes to this conclusion than if you did not already assume it. Think about this: dozens of very intelligent pollsters and analysts all worked with data that was replicated and resampled over and over again and all came to the wrong conclusion. They had a massive amount of data (compared to the average medical study) and resampled (repeated the experiment) hundreds of times; yet, they were wrong. How good do you really think a single medical study with 200 patients is going to be?
Have you ever wondered why it is that someone who does advanced work in mathematics has the same degree as someone who does advanced work in, say, art? They both have Doctorates of Philosophy because they both study subjective fields of human inquiry. Science is philosophy. We all look at things in different ways and our biases skew our sense of objective reality (they don’t skew reality, just our understanding of it). This is true even in fields that seem highly objective, like mathematics. A great example of this is in the field of probability. It really does matter whether or not you are a Bayesian or a Frequentist. Regardless of which philosophy you prefer (did you not know that you had a philosophical leaning?), you have to make certain assumptions about data in order to apply your equations, and here is where our biases rush in to help us make assumptions (not only am I a Bayesian, but I prefer the Jeffreys-Jaynes variety of Bayesianism). How you conduct science depends on your philosophical beliefs about the scientific process; how you analyze and categorize evidence and facts depends on your views of epistemology and ontology.
If two people can look at the same data and draw different conclusions, then you know that bias is present and not being mitigated adequately. We all have bias; but some are more aware of it than others. Only by being aware of it can we begin to mitigate it. We cannot (and shouldn’t try) to get rid of bias. Those who think that they are unbiased are usually the most dangerous folks; they are just unaware of their biases (or don’t care about them) and, in turn, are doing nothing to mitigate them. This is the danger of Scientism. The more you believe that you are right because ‘science’ or ‘facts’ say so, the less you truly know about science and facts and the less you are mitigating your personal biases. Bias is not just about your predisposition to dislike people who are different than you, and perhaps we should use the phrase cognitive disposition to respond as a less derisive term, but bias is shorter and easier to understand. If the word makes you uncomfortable, then good. Bias is easy to understand in the context of journalism and pollsters; most political junkies are aware that over 90% of journalists are left-leaning. Bias is harder for people to understand in the context of medical science, but the impact on outcomes (poll results, study findings, the patient’s diagnosis) is the same.
Thus, while the pollsters and pundits used science to inform their opinions of the data, most were unaware of how they were cognitively affected by their philosophies. In some cases, this means that they used statistical methods that were inappropriate, and in other cases it means that their political philosophy (and their assumptions about how people think and make decisions) misinformed their data interpretation. This happens in every scientific study. The wind is always going to blow, and your sail is your bias. You can’t get rid of your sail, you just have to point it in the best way possible. The boat is going to move regardless (even if you take the sail down). William James, in The Will to Believe, said,
We all, scientists and non-scientists, live on some inclined plane of credulity. The plain tips one way in one man, another way in another; and may he whose plane tips in no way be the first to cast a stone!
The plural of anecdote is not data. ― Marc Bekoff
How we interpret (and report) data affects how we and others synthesize and use it. Does the headline, “College educated whites went for Hillary” fairly represent the fact that Hillary got 51% of the college educated white vote? Maybe a better headline would have been, “Clinton and Trump split the white, college-educated vote.” Even worse, the margin of error for this exit-polling “fact” is enough that the truth may be that the majority of college-educated whites actually preferred Trump in the election. But the rhetorical implications of the various ways of reporting this data are enormous. Reporters and pundits make conscious choices about how to write such headlines.
Would you be surprised to know that Trump got a smaller percentage of the white vote than did Romney and a higher percentage of the Hispanic and African American vote than did Romney? But since fewer whites and non-whites voted in the 2016 election than in the 2012 election, we could choose to report that data by saying, “Trump received fewer black and Latino votes than Romney.” But so did Hillary compared to Obama. Fewer people voted in total. Obviously the point I am making is that how we frame (contextualize) data is immensely important and what context we choose to present for our data is subject to enormous bias.
I have made these points before in Words Matter and Trends… as these issues apply to medicine. Data without context is naked, and we must be painfully aware of how we clothe our data. Which facts we choose to emphasize (and which we tend to ignore) are incredibly important. How facts are spun as positives (or negatives) are ways that we bias others to believe our potentially incorrect beliefs. Science is just as guilty of this faux pas as are politicians and preachers. Have you ever said that a study proves or disproves something, or that a test rules something in or out? If you did, you are guilty of this same mistake. Studies and tests don’t prove things or disprove them, they simply change our level of certainty about a hypothesis. In some cases, when the data is widely variable and inconsistent, or when the test has poor utility (low sensitivity or specificity), a test or study may not change our pre-test probability at all. This was the case with polling data from the 2016 election: our pre-test assumption that a Clinton or Trump victory was equally likely should not have been changed at all given the poor quality of the data that was collected. This is also true of most scientific papers (for more on this concept, please read How Do I Know If A Study Is Valid?).
I want to pause here and talk about this notion of consensus, and the rise of what has been called consensus science. I regard consensus science as an extremely pernicious development that ought to be stopped cold in its tracks. Historically, the claim of consensus has been the first refuge of scoundrels; it is a way to avoid debate by claiming that the matter is already settled. Whenever you hear the consensus of scientists agrees on something or other, reach for your wallet, because you’re being had. Let’s be clear: the work of science has nothing whatever to do with consensus. Consensus is the business of politics. Science, on the contrary, requires only one investigator who happens to be right, which means that he or she has results that are verifiable by reference to the real world. In science consensus is irrelevant. What is relevant is reproducible results. The greatest scientists in history are great precisely because they broke with the consensus. There is no such thing as consensus science. If it’s consensus, it isn’t science. If it’s science, it isn’t consensus. Period. ― Michael Crichton
I cannot say this better than did Crichton so I won’t try. The consensus of the polls and pundits was wrong. Similarly, scientific consensus has been wrong about thousands of other scientific ideas in our past. Consensus is the calling card of Scientism. Galileo said, “In questions of science, the authority of a thousand is not worth the humble reasoning of a single individual.” Often what we call scientific consensus would be more accurately termed “prevailing bias.” This type of prevailing bias is dangerous when it leads to close-mindedness and bullying.
Scientific questions like, “Why were the polls so wrong?” or, “What causes heart disease?” are complex and multifactorial. We don’t know all the issues that need to be considered to even begin to answer questions like these. Humans naturally tend to reduce such incredibly complex and convoluted problems down into over-simplified causes so that we can wrap our minds around them. Here’s one such trope from the election: “Whites voted for Trump and non-whites voted for Clinton.” This vast oversimplification of why Trump won and Clinton lost is frustratingly misleading, but if you are predisposed to want to believe that this is the answer, then those words in The Guardian will suffice. Why not report, “People on the coast voted for Clinton and inland folks voted for Trump,” or “People in big cities voted for Clinton and people in smaller cities and rural areas voted for Trump,” or old people versus young people, rich versus poor, bankers versus truck drivers, or violists versus engineers?
It would be wrong to reduce a complex question down to any of these over-simplified explanations, but when you see it done, you can tell the bias of the author. If someone studies dietary factors associated with Alzheimer’s disease, the choice of which factors they chose to study reveals his bias. What’s more, even though all of those issues may be relevant to the problem, when the evidence is presented in such a reductionist and absolute way, we quickly lose perspective of how important the issue truly is. So if only 51% of college-educated whites voted for Clinton, why present that particular fact (out of context and without a measure of the magnitude of effect)? The truth would appear to be that a college education was not really relevant to the election outcome. How much does eating hot dogs increase my chance of GI cancer? I’m not doubting that it does, but if the magnitude of effect is as little as it is, I will continue eating hot dogs and not worry about it.
We are curious and we all want to know the mechanisms of the diseases we treat or why people vote the way they do, etc. Yet, we must be careful not to too quickly fill in details that we don’t really understand. Not everything has to be understood to be known. When we reduce down complex problems, we almost always create misconceptions, and these misconceptions may impede progress and understanding of what is actually a complex issue. One of the my favorite medical examples: meconium aspiration syndrome (MAS). There is a comfort for the physician in thinking of MAS as a disease caused by the aspiration of meconium during birth; but the reality is that the meconium likely has little to nothing to do with the often fatal variety of MAS. We oversimplified a complex problem, but the false idea has been incredibly persistent. We spent decades doing non-evidence based interventions like amnioinfusion or deep suctioning at the perineum because it made sense. It made sense because we reduced a complex problem down to simple elements (that were, as it turns out, wrong or at least incomplete). Other examples include the cholesterol hypothesis of heart disease or the mechanical theories of cervical insufficiency, etc.
The quest for absolute certainty is an immature, if not infantile, trait of thinking. ― Herbert Feigl
The truth is that the pollsters’ main sin was over-representing their levels of confidence. Different pollsters looks at the same data in remarkably different ways. Out of 61 tracking polls going into the election, only one (the L.A. Times/USC poll) gave Trump a lead. Those individual polls, it turns out, over-sampled minority votes (or under-sampled white voters, depending upon your bias). Why did this incorrect sampling happen? Bias. Pollsters were over-sold on the narrative of the changing demographics of America. Some have admitted that they felt it was impossible for any Republican to win ever again because of this. So they made sampling assumptions in the polls that were biased to produce that result (I am not saying this was done consciously – they honestly believed that what they were doing was correct).
Here’s the lesson: We make serious mistakes in science and in decision making when we pick the outcome before we collect (or analyze) the data. We must let the facts lead to a conclusion, not our conclusion lead to the facts. This principle is true for every scientific experiment ever conducted. The pollsters really didn’t know what percentage of whites and non-whites would vote in this election (this was much easier in the 2012 election which was rhetorically similar to the 2008 election). But rather than express this uncertainty in reporting the data, the pollsters published confidence intervals and margins of error that were too narrow than the data deserved (and this over-selling of confidence is promoted by a sense of competition with other pollsters, just like scientific investigators in every field seek to one-up their colleagues).
This already biased polling data was then used by outfits like fivethirtyeight.com to run through all the scenarios and make a projection of the likely outcome of the race. A group at Princeton reported a 99% chance that Clinton would win. Fivethirtyeight gave Clinton the lowest pre-election probability of winning at 71.4%. In other words, the algorithms used by fivethirtyeight and Princeton and others looked at basically the same data and, by making different philosophical assumptions, used the same probability science to estimate the chance of the two candidates winning and came up with wildly different predictions from one another (from a low of 71.4% to a high of a 99% chance of a Clinton victory). These models of reality were all vastly different than actual reality (a 0% chance of a Clinton victory).
But if we look closer at both how much the polls changed throughout the season and how much prognosticators changed their predictions throughout the season, then what we note is very wide variation. This amount of variation alone can be statistically tied to the level of uncertainty in the data, which is a product of both the pollsters’ misassumptions about sampling and the pundits’ overconfidence in that data (and some poor statistical methodology). Error begets error. Nassim Taleb, author of Black Swan, Antifragile, and Fooled By Randomness, consistently criticized the statistical methodologies of fivethirtyeight and other outlets throughout the last year. If you are interested in some statistical heavy-lifting, read his excellent analysis here.
What the pundits should have said was, “I don’t know who has the advantage” and that would have been closer to the truth (this was Taleb’s own position). In other words, when we communicate scientific knowledge, it is important to report both the magnitude of effect of the observation and the probability that the “fact” is true (our confidence level). This underscores again the importance of epistemology (and I would argue Bayesian probabilistic reasoning). One of the basic tenets of Bayesian inference is that when no good data is available to estimate the probability of an event, then we just assume that the event is as likely to occur as to not occur (50/50 chance). This intuitive estimate, as it turns out, was much closer to the election outcome than any pundit’s prediction. But we didn’t know what we didn’t know because people are bad at saying the words, “I don’t know.” A side note is that very often our intuition is actually better than shoddy attempts at explaining things “scientifically.” This theme is consistent in Taleb’s writings. For example, most people unexposed to polling results (which tend to bias their opinions) would have stated that they were not sure who would win. That was a better answer than was Nate Silver’s at the fivethirtyeight blog. Intuition (System 1 thinking) is a powerful tool when it is fed with good data and is mitigated for bias (but, yes, that’s the hard part).
Nassim Taleb is less subtle in his criticisms of Scientism and what he calls the IYI class (intellectual yet idiot):
With psychology papers replicating less than 40%, dietary advice reversing after 30 years of fatphobia, macroeconomic analysis working worse than astrology, the appointment of Bernanke who was less than clueless of the risks, and pharmaceutical trials replicating at best only 1/3 of the time, people are perfectly entitled to rely on their own ancestral instinct and listen to their grandmothers (or Montaigne and such filtered classical knowledge) with a better track record than these policymaking goons.
Indeed one can see that these academico-bureaucrats who feel entitled to run our lives aren’t even rigorous, whether in medical statistics or policymaking. They can’t tell science from scientism — in fact in their eyes scientism looks more scientific than real science.
Taleb has written at length about how poor statistical science affects policy-making (mostly in the economic realm). But we see this in medical science as well. Do sequential compression devices used at the time of cesarean delivery reduce the risk of pulmonary embolism? No. But they are almost universally used in hospitals across America and have become “policy.” Such policies are hard to reverse. In medicine, we create de facto standards of care based on low-confidence, poor evidence. Scientific studies should be required to estimate the level of confidence that the hypothesis under consideration is true (and this is completely different than what a P-value tells us), as well as the magnitude of the effect observed or level of importance. Just because something is likely to be true doesn’t mean it’s important.
Consequentialism is a moral hindrance to knowledge.
Science has long been hindered by dogma. Most great innovations come from those who have been unencumbered by the weight of preconceptions. By age 24, Newton had conceptualized gravity and discovered the calculus. Semmelweis had discovered that hand-washing could prevent puerperal sepsis by age 29. Faraday had invented the electric motor by age 24. Thomas Jefferson wrote the Declaration of Independence at age 33. Why so young? Because these men and dozens of others had not already decided the limitations of their knowledge. They did not suffer from the ‘persistence of ideas’ bias. They did not know what was possible (or impossible). They looked at the world differently than their older contemporaries because they had not already learned ‘the way it was.’ Therefore, they had less motivation to skew the data they observed into a prespecified direction or to make the facts fit a narrative. Again, they were more likely to abide by the howardism, We must let the facts lead to a conclusion, not our conclusion lead to the facts.
Much of pesudo-science starts with someone stating, “I know I’m right, now I just have to prove it!” This opens the door to often inextricable bias. I believe this is a form of consequentialism.
Consequentialism is a moral philosophy best explained with the aphorism, “The ends justifies the means.” In various contexts, the idea is that the desired end (which is presumably good) justifies whatever actions are needed to achieve that end along the way. Actions that might normally be considered unethical (at least from a deontological perspective) are justifiable because the end-goal is worth it. Of course, this presumes two things: that the end really is worth it, and that the impact of all the otherwise unethical actions along the way don’t outweigh the supposed good of the outcome. Such pseudo-Machiavellian philosophy is really just an excuse to justify human depravity (Machiavelli never said the ends justifies the means). Put another way, if you can’t get to a good outcome by using moral actions, the outcome is probably not actually good.
What does this have to do with the election and science? Simply this: when a scientist (or pollster, politician, journalist, or you) has predetermined the outcome or the conclusion you believe should be, then all the data along the way is skewed according to this bias. You are subject to overwhelming cognitive bias. You have fallen prey to Jaynes’ mind projection fallacy. Real science lets the data speak for itself. But most science, as practiced, conforms data to fit a predetermined narrative (the narrative fallacy). However, what we think is the right outcome or conclusion, determined before the data is collected, may or may not be correct. True open-mindedness is not having a preconception about what should be, what is possible or impossible, what is or has been or will be, but only a desire to discover truth and knowledge, regardless of where it might lead.
Just as pundits and pollsters were blind to the reality of a looming Trump victory (and practically inconsolable at the surprise that they had been so wrong), so too do medical scientists conduct studies which are designed with enough implicit bias to tweak the data to fit their agendas. Scientists should seek to disprove their hypothesis, not prove it. There is a reason why the triple blinded, placebo-controlled, randomized trial is the gold standard (though not infallible) – to remove bias. The idea that we should seek to disprove what we believe is not just an axiom – it’s foundational to properly conduct experiments. Be on the lookout for people who pick winners first (people or ideas) and then manipulate the game (rules or data) to make it happen.
Published Date : September 14, 2016
Categories : Evidence Based Medicine
The financial consequences of poor prescribing habits, as detailed in Which Drug Should I Prescribe?, are simply enormous. Recall that just one physician, making poor prescribing decisions for only 500 patients, could unnecessarily add nearly a quarter of a billion dollars in cost to the healthcare system in just 10 years. In the case of prescribing habits, physicians personally gain from their poor choices only by receiving adoration from drug reps along with free lunches and dinners. But what about other treatment decisions? How much cost is added to the system when physicians deviate from evidence-based practice guidelines, and is there a financial benefit to them for doing so?
Let’s look at a practical example.
Imagine a small Ob/Gyn practice with four providers. The four providers see 1,000 young women a year between the ages of 17-20 who desire birth control (that is, each physician sees 250 of these patients). The evidence-based approach to treating these patients would be to give them a long-acting reversible contraceptive (LARC) and to not do a pap smear (of course, they should still have appropriate screenings for mental health, substance abuse, etc. as well as testing for gonorrhea and chlamydia and other interventions as needed).
If each of these women presented initially at age 17 or 18 desiring birth control and received a three-year birth control device (e.g, Nexplanon or Skyla), then it is likely that a majority of them would not return for yearly visits until the three year life of the birth control had passed. It is also likely that only 1-3 of the 1000 women would become pregnant over the three year period while using a LARC. Gynecologists for decades have tied the pap smear to the yearly female visit. As a consequence, most young women, when they learn that they don’t need a pap every year, don’t come back for a visit unless they need birth control or have some problem.
The most common need, of course, is birth control. But when women have a LARC and know that they don’t need a yearly pap smear, they are even less likely to return just for a screening visit. Admittedly, gynecologists need to do a better job of “adding value” to the yearly visit and focus on things that truly improve the quality of life for patients – like mental health and substance abuse counseling – but these things take time and it’s much quicker just do an unnecessary physical exam and move on. Physicians use the need for a birth control prescription – and the lie that they need a pap smear in order to get a prescription for birth control – in order to force women back to the office each year. What’s worse, many young women don’t go to a gynecologist in the first place for birth control because they do dread having a pelvic exam; they then become unintentionally pregnant after relying on condoms or coitus interruptus.
In the following example, the evidence-based (EB) physician sees an 18-year-old patient who desires birth control; he charges her for a birth control counseling visit and charges her for the insertion of a Nexplanon, which will last three years and provides extraordinary efficacy against pregnancy. He sees her each year afterwards for screening for STDs and other age-appropriate counseling, but he does not do a pap smear until she turns 21.
The non-EB physician sees the same 18-year-old patient who desires birth control and prescribes a brand-name birth control pill (at an average cost of $120 per month and with an 8.4% failure rate). He insists that she first have a pap smear since she is sexually active and he plans to continue doing pap smears each year when she returns for a birth control refill. He tells her scary stories about a patient he remembers her age who was having sex and got cervical cancer but thankfully he caught it with a pap smear (of course, that patient didn’t have cervical caner – she had dysplasia – but these little white lies are common in medicine). He doesn’t adequately screen her for mood disorders, substance abuse, or other issues relevant to her age group, but he does make a lot of money off of her; and he could care less about the psychological harm he might have caused her with his scary stories.
About 30% of women in this age group will have an abnormal pap smear if tested, and about 13.5% would have a pap smear showing LSIL, HSIL, or ASCUS with positive high risk HPV. The non-EBM physician would then do colposcopies on these 13.5% of women, along with short interval repeat pap smears (e.g, every 4-6 months) on the women with abnormal pap smears. About 15% of the women who receive colposcopy will have a biopsy with a moderate or severe dysplastic lesion, and the non-EBM physician will then do an unnecessary and potentially sterilizing LEEP procedure on those patients.
Since he gave these women birth control pills, 84 of the 1,000 patients will become pregnant each year, and this will lead to significant costs for caring for these pregnant women and delivering these babies. In fact, 252 of the 1000 women will become pregnant over the next three years (compared to 1-3 women who received a LARC). Ironically, the very reason why the patients came to the doctor in the first place is the most neglected, with nearly 1 in 4 becoming pregnant because of the poor decisions of the non-EB physician. The chart below shows the financial repercussions for the first year of care for these patients and for three years of care (since that is the useful life of a Nexplanon or Skyla LARC):

The differences are dramatic: the evidence-based physician has perhaps 3 pregnancies per 1000 patients and no issues with pap smears since none were done. I have no doubt that many of the women returned dissatisfied with the Nexplanon and some likely discontinued and switched methods, and I have allowed for return visits each year. A greater number of women who received birth control pills will return with problems and a desire to switch. But over 3 years, 252 of the women who were given birth control pills will become pregnant.
These young women came to get birth control and were instead victimized. The effects of unintended pregnancy on young women are profound. Women who have children under age 18 are nearly twice as likely to never graduate high school, nearly two-thirds live in poverty and receive government assistance, three-quarters never receive child support, and their children grow up underperforming in school. These are dramatic societal costs that must be considered a consequence of physicians ignoring evidence-based guidelines.
So what about the money? The physician who follows evidence-based guidelines will collect about $350,000 over the three year period; whereas the physician who does not will collect nearly $1.3 million in the same time. The physicians are financially incentivized to hurt young women. These extra monetary gains for the physician cost our healthcare system nearly 6.3 million dollars more. This story can be repeated for a variety of other medical problems in every speciality.
Another Ob/Gyn example: a physician who treats abnormal uterine bleeding with a hysterectomy when a lesser alternative might have sufficed (such as a Mirena IUD, birth control pills, or an endometrial ablation). The physician is financially incentivized to perform a hysterectomy because her fee is higher for that service compared to other, more appropriate services; but in order for the physician to make a few hundred dollars more, the healthcare system is drained of many thousands of dollars (the hospital charges for a hysterectomy can be enormous) and the patient is exposed to a higher risk procedure when a lower risk intervention was likely to work just as well.
The current model of financially incentivizing physicians to provide as much care as possible (what is called fee for service) is bankrupting our healthcare system and harming patients with too many interventions, too many prescriptions, and too much care. No good alternative to this system has been proposed. But fee for service provides no incentive for physicians to choose lower cost treatments, to prescribe less expensive drugs, or to perform expensive interventions only when truly needed. No good alternative to fee for service has been proposed, but every important player in healthcare realizes that the model needs to be changed in order to improve the quality of care and reduce costs.
The financial services industry faces a similar crisis. Currently, most financial advisors make money off of selling products, collecting fees for the transactions they conduct and the financial products that they sell, and, in some cases, residual fees from future earnings. This incentivizes advisors to sell products (stocks, bonds, equities, etc.) that produce the largest fees or the biggest return for them, not for the client. New federal rules are attempting to address this problem by requiring financial advisors to comply with fiduciary standards, meaning that they must put the clients’ needs above their own. How is this incentivized? A fiduciary advisor makes more money only if the client does; the fiduciary rules outlaw transactional fee (like selling an investment product) and instead tie the advisor’s fees to future client earnings. Full disclosure of conflicts of interest are also required. Essentially, the financial services industry is transitioning from a fee for service model (how many investment products can I sell?) to a fee for better outcomes model (I’ll only make more money if my client does).
In theory, physicians should comply with fiduciary rules for patient care because of our professional oath; doing what is best for patients without exploiting them is the most essential ethic of any medical professional. But professionalism among medical doctors is a true rarity, and the proof of this is the vast majority of physicians who choose the unethical approach of rejecting evidence-based guidelines and instead exploiting patients for financial gain.
Now I’m not suggesting that most physicians who don’t follow evidence-based guidelines do so because they have consciously chosen to financially exploit the patient, but in the example above of a 1,000 patients in a four physician group, if those physicians choose to follow evidence-based guidelines, they would likely not need the fourth physician and they wouldn’t be able to pay her. The finances of medical practice dictate far too many decisions, and sometimes this influence is subconscious (though many times it is not). Physicians are smart, and they are too good at couching their decisions to over-utilize interventions as if it’s a benefit to those patients: it’s never because physicians want to make more money doing it, it’s always because they are doing what’s best for patients. But the example above, which is typical for similar issues in many specialities, shows that outcomes are not better and the cost of not following evidence-based guidelines are extraordinary.
Physicians need to be financially incentivized to follow ethical, fiduciary principles. The Hippocratic Oath isn’t cutting it. Financial services advisors under fiduciary guidelines are paid more only if the client does well, and so too doctors should make more money only if their patients do well. In a $55 visit, I can choose to prescribe an inexpensive generic drug for a problem (at a cost of $48 a year) or I can choose to prescribe an expensive branded drug (at a cost of $4200 a year). Insurance companies need to recognize this and reward the physician who makes good decisions. It is much better to pay the physician another $100 to have the time to talk to the patient and educate her than it is to pay $4200 a year for the poor decision. Why not pay physicians as much for IUD insertions as they are payed for hysterectomies? Yes, I am quite serious. You would see so many IUDs being inserted that it would make your head spin, but the cost of healthcare overall would drop dramatically and patient outcomes would improve. High school graduation rates would increase. Poverty would decrease. Paychecks would go up as less money was spent on health insurance premiums. Why not pay more for vaginal deliveries than cesarean deliveries? In general, paying more for the good care that physicians provide and less for the bad care physicians provide is the solution. But what is good care and what is bad care? That’s the struggle.
I suggest three things.
A physician who does 10 hysterectomies per year should, in most cases, be paid more than a physician who does 100 hysterectomies per year. The number of unnecessary surgeries and interventions in all disciplines of medicine is staggering, and it results in high-cost, low-quality healthcare that is bankrupting the US system. I wish that the Hippocratic Oath were enough and that physicians always did what was best for their patients even if it meant making less money, but this wish is a pipe dream. We need appropriate financial incentives.
Published Date : August 30, 2016
Categories : Cognitive Bias, Evidence Based Medicine
Published Date : August 29, 2016
Categories : Evidence Based Medicine

Once the diagnosis is made correctly, the treatments begin. Selection of prescription drugs is one of the important (and costly) things that physicians do. How do we decide which drugs to use? Or, a better question, How should we decide?
First, let’s consider a patient who represents an almost typical case these days: a diabetic who has neuropathy, hypertension, hyperlipidemia, GERD, hypothyroidism, bipolar depression, and an overactive bladder. Even if this might not represent the problem list of your typical patient, it likely represents the problem list of any two patients (the average American between ages 19 and 64 takes 12 prescription drugs per years – many of which are unnecessary).
For each issue on the problem list, let’s select two common treatments. Doctor A tries to use lower cost drugs and generics when available. Doctor B favors newer drugs and believes that he is providing world-class medicine (at least that’s what the drug reps keep telling him). Let’s see what it costs Doctor A and Doctor B to treat this patient each year. Also, we’ll see what the ten year cost of treatment is and then magnify that times 500 patients (to represent a typical treatment panel of patients that a primary care doctor might have).
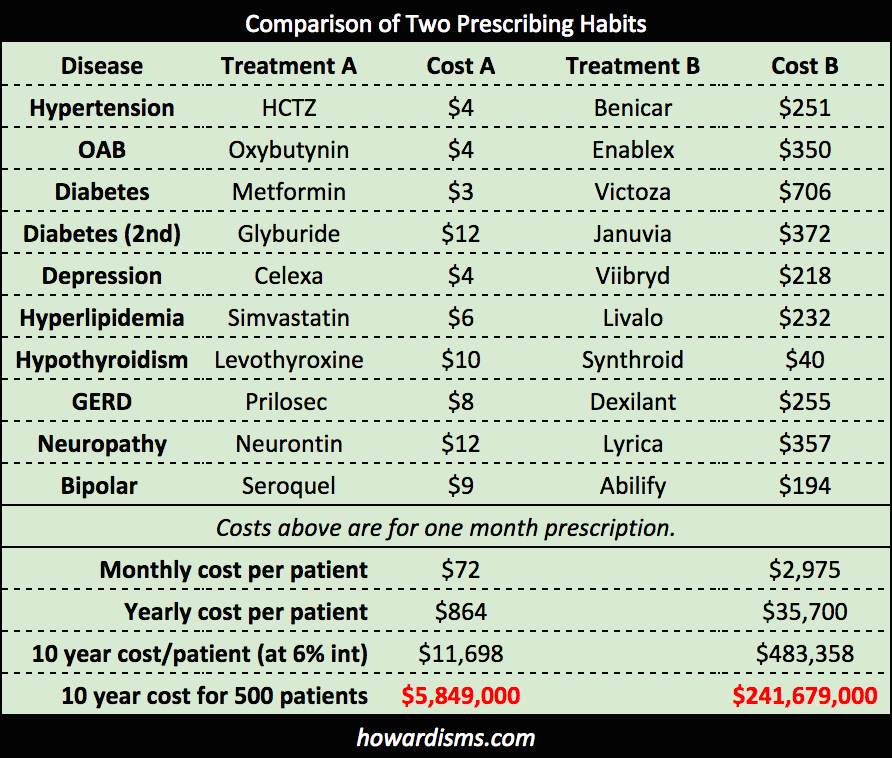
The difference in the two approaches is dramatic: Doctor B has spent nearly a 1/4 billion dollars more than Doctor A in just 10 years on just 500 patients. Add to this the increased costs of poorly selected short-term medications (like choosing Fondaparinux at $586/day versus Lovenox at $9.25/day, or choosing Benicar at $251/day rather than Cozaar at $8/day), unnecessarily prescribed medications (like antibiotics for earaches, sore throats, and sinus infections), unnecessary tests (like CT scans for headaches or imaging for low back pain), and the cost differences between Doctor A and Doctor B soar, all based upon decisions that the two doctors make in different ways.
In a career, Doctor B may cost the healthcare system easily $1 billion more than Doctor A. The cost of prescription drugs (and more importantly, the way doctors decide to use them) more than explains the run-away costs and low value of US healthcare. The top 100 brand-name prescription drugs in the US (by dollar amounts) netted $194 billion in sales a year as of 2015 (plus pharmacy mark-ups, etc.). This list of drugs includes Lyrica, Januvia, Dexilant, Benicar, Victoza, Synthroid, and Abilify (all mentioned above) plus Crestor (it recently went generic so I have substituted the similarly priced, non-generic Livalo), Vesicare (similarly priced to the Enablex listed above), and Pristiq (which is actually more expense than the Viibryd I used on the list – Viibryd is one of the top 100 prescribed branded drugs, just not a top 100 money maker). So Doctor B’s choice of drugs is representative for the choices many doctors are making in the US.
Now in fairness, the most prescribed drugs by number of prescriptions are generics, but because they are so inexpensive, they do not make the money list. Doctor A’s choice of Metformin, Levothyroxine, and Omeprazole (generic Prilosec) are all among the Top 10 most prescribed generics. Unfortunately, the most prescribed drug of all (with 123 million prescriptions in 2015) was generic Lortab.
So who’s right, Dr. A or Dr. B? Let’s go through a process to determine what drug we should prescribe.
Is a drug treatment necessary?
Just because a patient has a diagnosis doesn’t mean she necessarily needs a drug to match it. Physicians tend to overestimate the benefits of most treatments and do a poor job of conveying the potential benefits (and risks) to patients. Non-medical treatments (like lifestyle changes, counseling, etc.) are undervalued and perceived as less effective or just too much work. Providers often feel like they have to write a prescription or they will have an unsatisfied patient (in other words, they feel that if a patient presents with a complaint, it must be addressed with an intervention rather than just education and reassurance). Even worse, many clinicians believe that if they prescribe a medication during a visit, they can bill for a higher level visit, so they feel financially rewarded for prescribing. For example,
In general, overuse of prescription medications happens for the following reasons:
Once it is decided that a drug is necessary for treatment, the next question is, Which one?
Which drug is appropriate?
In order to determine this, we must first decide what the goal of treatment is in order to select a medication that satisfies that goal. This sounds obvious, but it isn’t always done appropriately. The next part is trickier. In general, we need to select the lowest-cost medication that fulfills this treatment goal. Dr. A has done this in the above example quite well. Dr. B would rationalize his choices by adding that he has also picked either the most effective drug and/or the one with the least side effects. This rationale sounds attractive, and drug companies prey on the desire of physicians to use the best drug with the fewest side effects (and the ego-boosting idea that they are being innovative). But it is the wrong strategy. Here’s why.
Let’s say that Drug A is 90% effective at treating the desired condition and carries with it a 5% risk of an undesirable side effect. Meanwhile, Drug B is 95% effective at treating the condition and carries only a 2.5% risk of the side effect. Drug B is then marketed as having half the number of treatment failures as Drug A and half the number of side effects as Drug A. Drug A costs $4 while Drug B costs $350. So which drug should we use? If 100 people use Drug B, then approximately 92 will be treated successfully without the side effect at a cost of $386,400 per year. Eight people will remain untreated. If 100 people use Drug A, then approximately 85 people will be treated successfully without the side effect at a cost of $4,080 per year. After failing Drug A, an additional 7 people will use Drug B successfully at a cost of $29,400 per year, with 8 people still untreated. This try-and-fail or stepwise approach, rather than the “Gold Standard” approach, treated just as many people successfully but saved $352,920 per 100 people per year.
This scenario assumes that such dramatic differences between the two drugs even exist. The truth is that this is rarely the case. Such dramatic differences in side effects and efficacy do not exist for the drugs listed in the scenario above. What’s worse, in many cases the more expensive drug is actually inferior. HCTZ has long had superior mortality benefit data compared to ACE-Is and ARBs, but due to clever marketing, has never been utilized as much as it should be. Metformin is simply one of the best (and cheapest) drugs for diabetes, yet no one markets it and there are no samples in the supply closet. Fondaparinux is an important drug for the rare person who has heparin-induced thrombocytopenia (HIT), but the incidence of HIT among users of prophylactic Lovenox is less than 1/1000, hardly justifying the 63-fold increased price of fondaparinux. The clinical differences between Cozaar and Benicar can hardly begin to justify the 31-fold price difference. To decide by policy that every patient with overactive bladder should receive Vesicare ($300), Detrol LA ($320), or Enablex ($350) as a first line drug when most patients are satisfied with Oxybutynin ($4) is the attitude that is bankrupting US healthcare. In some cases, physicians prescribe the exact same drug at a costlier price (e.g. Sarafem for $486 instead of the chemically identical fluoxetine for $6).
A word of caution about interpreting drug comparison trials: drug companies have ten of billions of dollars at stake when marketing new drugs. The trials that are quoted to you are produced and funded by those drug companies. They only publish the studies that show positive results. Drug studies are, by far, the most biased of all publications so be incredibly careful in believing the bottom line from the studies. Here’s a howardism,
If the drug were really that good, it wouldn’t need to be marketed so aggressively.
Even when one drug is substantially better than another, it still may not be appropriate to prescribe it. Many times, the prohibitive cost of the perceived “better” drug prevents patients from actually getting and maintaining use of the drug, leading to significantly poorer outcomes than would have existed with the “inferior” drug. The best drug is the one the patient can afford to take.
Thus, pick the drug that is designed to achieve the desired goal that is least expensive (or at least pick a drug that is available as a generic), then specifically decide why that drug is not an option before picking a more expensive one (e.g. the patient is allergic to the drug, the patient previously failed the drug, etc.). (Wonder how much drugs cost? All the prices here are taken from goodrx.com).
What influences determine the drugs that clinicians prescribe?
There are two facts about drug company marketing. The first is the physicians do not believe that they are influenced by drug company advertisements, representatives, free lunches and dinners, pens, sampling, CME-events, etc. The second is that drug company marketing is the number one influence on clinicians’ prescribing habits. In 2012, US drug companies spent $3 billion marketing to consumers while spending $24 billion marketing directly to doctors. They spend that money because they know it yields returns. Remember that just one Dr. B is worth nearly 1/4 of a billion dollars in a ten year period to pharmaceutical companies. They are more than happy to buy as many meals as it takes. But doesn’t this money support research? It’s true that most drug companies spend billions per year on research and development, but the total R&D expenditures are usually about half of marketing expenses alone, and obviously a fraction of the $350+ billion revenues. But don’t samples help me take care of my poor patients? No. They help influence your prescribing habits and they give you the impression that the drug is a highly desirable miracle that would be wonderful to give away to the needy because it’s just that good. What can help you take care of your patients are $4 generic drugs. Read more about the financials of the industry and the rising costs of drugs here.
These problems would be much worse than they are if insurance companies (“the evil insurance companies”) didn’t have prescribing tiers that force patients to ask their doctors for cheaper alternatives and if they didn’t deny coverage entirely for many brand-name drugs. But it is still an enormous problem, resulting in hundreds of billions of dollars of excess cost to the US healthcare system each year.
Simply by being more like Dr. A and less like Dr. B, physicians could rapidly and dramatically reduce the cost of US healthcare.
Published Date : August 25, 2016
Categories : Cognitive Bias

All men make mistakes, but a good man yields when he knows his course is wrong, and repairs the evil. The only crime is pride.
— Sophocles, Antigone
(Thanks to my friend Michelle Tanner, MD who contributed immensely to this article).
In the post Cognitive Bias, we went over a list of cognitives biases that may affect our clinical decisions. There are many more, and sometimes these biases are given different names. Rather than use the word bias, many authors, including the thought-leader in this field, Pat Croskerry, prefer the term cognitive dispositions to respond (CDR) to describe many situations where clinicians’ cognitive processes might be distorted, including the use of inappropriate heuristics, cognitive biases, logical fallacies, and other mental errors. The term CDR is thought to carry less of a negative connotation, and indeed, physicians have been resistant to interventions aimed at increasing awareness of and reducing errors due to cognitive biases.
After the publication of the 2000 Institute of Medicine Report To Err is Human, which attributed up to 98,000 deaths per year to medical errors, many efforts were made to reduce errors in our practices and systems. Development of multidisciplinary teams, computerized order entry, clinical guidelines, and quality improvement task forces have attempted to lessen medical errors and their impact on patients. We have seen an increased emphasis on things like medication safety cross-checking, reduction in resident work hours, using checklists in hospital order sets or ‘time-outs’ in the operating room. But most serious medical errors actually stems from misdiagnosis. Yes, every now and again a patient might have surgery on the wrong side or receive a medication that interacts with another medication, but at any given time, up to 15% of patients admitted to the hospital are being treated for the wrong diagnosis – with interventions that carry risk – while the actual cause of their symptoms remains unknown and likely untreated. To Err Is Human noted that postmortem causes of death were different from antemortem diagnoses 40% of the time in autopsies! How many of those deaths might have been prevented if physicians had been treating the correct diagnosis?
Most of these failures of diagnosis (probably two-thirds) are related to CDRs and lot of work has been done since 2000 to elucidate various causes and interventions, but physicians have been resistant to being told that there might be a problem with how they think. Physicians love to blame medical errors on someone or something else – thus the focus has been on resident’s lack of sleep or medication interaction checking. Seeking to reduce physicians resistance due to a feeling of being criticized is a prime reason why Croskerry and others prefer to use the term cognitive disposition to respond rather than negative words like bias or fallacy. I’m happy with either term because I’m not sure that relabeling will change the main problem: physicians tend to be a bit narcissistic and therefore resistant to the idea that all of us are biased and all of us have to actively work to monitor those biases and make decisions that are overly-influenced by them.
We make poor decisions for one of two reasons: either we lack information or we don’t apply what we know correctly. Riegleman, in his 1991 book Minimizing medical mistakes: the art of medical decision making, called this ‘errors of ignorance’ and ‘errors of implementation.’ One of the goals of To Err is Human was to create an environment where medical errors were attributed to systematic rather than personal failures, hoping to make progress in reducing error by de-emphasizing individual blame. Our focus here, of course, is to evaluate the errors of implementation. Graber et al., in 2002, further categorized diagnostic errors into three types: No-fault errors, system errors, and cognitive errors. No-fault errors will always happen (like when our hypothetical physician failed to diagnose mesenteric ischemia despite doing the correct work-up). System errors have been explored heavily since the publication of To Err is Human. But the cognitive errors remain and understanding our CDRs (our biases, etc.) is the first step to reducing this type of error.
Croskerry divides the CDRs into the following categories:
Some additional biases mentioned above include the bandwagon effect (doing something just because every one else does, like giving magnesium to women in premature labor), ambiguity effect (picking a diagnosis or treatment because more is known about it, like the outcome), contrast effect (minimizing the treatment of one patient because, in contrast, her problems pale in comparison to the last patient), belief bias (accepting or rejecting data based on its conclusion or whether it fits with what one already believes rather than on the strength of the data itself), ego bias (overestimating the prognosis of your patients compared to that of others’ patients), and zebra retreat (not pursuing a suspected rare diagnosis out of fear of being view negatively by colleagues or others for wasting time, resources, etc.).
We are all vulnerable to cognitive dispositions that can lead to error. Just being aware of this is meaningful and can make us less likely to make these mistakes, but we need to do more. We need to actively work to de-bias ourselves. Let’s look at some strategies for this (adapted from Croskerry):
Develop insight/awareness: Education about CDRs is a crucial first step to reducing their impact on our clinical thinking, but it cannot stop with reading an article or a book. We have to look for examples of them in our own practices and integrate our understanding of CDRs into our quality improvement processes. We need to identify our biases and how they affect our decision-making and diagnosis formulation. An analysis of cognitive errors (and their root causes) should be a part of every peer review process, quality improvement meetings, and morbidity and mortality conferences. Most cases that are reviewed in these formats are selected because a less than optimal outcome occurred; the root cause (or at least a major contributor) in most cases was a cognitive error.
Consider alternatives: We need to establish forced consideration of alternative possibilities, both in our own practices and in how and what we teach; considering alternatives should be a part of how we teach medicine routinely. Always ask the question, “What else could this be?” Ask yourself, ask your learner, ask your consultant. The ensuing conversation is perhaps the most educational thing we can ever do. Even when the diagnosis is obvious, always ask the question. This needs to become part of the culture of medicine.
Metacognition: We all need to continually examine and reflect on our thinking processes actively, and not just when things go wrong. Even when things go right, it is a meaningful and important step to consider why things went right. We focus to much on negative outcomes (this is a form of bias); consequently, we develop a skewed sense of what contributed to the negative outcome. So try thinking about what went right as well, reinforcing the good things in our clinical processes.
Decrease reliance on memory: In the pre-computer days, a highly valued quality in a physician was a good memory. Unfortunately, medical schools today still emphasizes this skill, selecting students who might excel in rote memorization but lag behind in critical thinking skills. In the 1950s, memory was everything: there was no quick way of searching the literature, of comprehensively checking drug interactions, of finding the latest treatment guidelines, etc. But today, memory is our greatest weakness. Our memories are poor and biased, and there is more data that we need to have mastery of than ever before in order to be a good doctor. So stop relying on your memory. We need to encourage the habitual use of cognitive aids, whether that’s mnemonics, practice guidelines, algorithms, or computers. If you don’t treat a particular disease every week, then look it up each time you encounter it. If you don’t use a particular drug all the time, then cross check the dose and interactions every time you prescribe it. Even if you do treat a particular disease every day, you should still do a comprehensive literature search every 6 months or so (yearly at the very least).
Many physicians are sorely dated in their treatment. What little new information they learn often comes from the worst sources: drug and product reps, throw-away journals, popular media, and even TV commercials. Education is a life-long process. Young physicians need to develop the habits of life-long learning early. Today, this means relying on electronic databases, practice guidelines, etc. as part of daily practice. I, for one, use Pubmed at least five times a day (and I feel like I’m pretty up-to-date in my area of expertise).
Our memory, as a multitude of psychological experiments have shown, are among our worst assets. Stop trusting it.
Specific training: We need to identify specific flaws in our thinking and specific biases and direct efforts to overcome them. For example, the area that seems to contribute most to misdiagnosis relates to a poor understanding of Bayesian probabilities and inference, so specific training in Bayesian probabilities might be in order, or learning from examples of popular biases, like distinguishing correlation from causation, etc.
Simulation: We should use mental rehearsal and visualization as well as practical simulation/videos exhibiting right and wrong approaches. Though mental rehearsal may sound like a waste of your time, it is a powerful tool. If we appropriately employ metacognition, mental rehearsal of scenarios is a natural extension. Remember, one of our goals is to make our System 1 thinking better by employing System 2 thinking when we have time to do so (packing the parachute correctly). So a practical simulation in shoulder dystocia, done in a System 2 manner, will make our “instinctual” responses (the System 1 responses) better in the heat of the moment when the real shoulder dystocia happens. A real shoulder dystocia is no time to learn; you either have an absolute and definitive pathway in your mind of how you will deliver the baby before it suffers permanent injury or you don’t. But this is true even for things like making differential diagnoses. A howardism: practice does not make perfect, but good practice certainly helps get us closer. A corollary of this axiom is that bad practice makes a bad doctor; unfortunately, a lot of people have been packing the parachute incorrectly for many years and they have gotten lucky with the way the wind was blowing when they jumped out of the plane.
Cognitive forcing strategies: We need to develop specific and general strategies to avoid bias in clinical situations. We can use our clinical processes and approaches to force us to think and avoid certain biases, even when we otherwise would not. Always asking the question, “What else could this be?” is an example of a cognitive forcing strategy. Our heuristics and clinical algorithms should incorporate cognitive forcing strategies. For example, an order sheet might ask you to provide a reason why you have elected not to use a preoperative antibiotic or thromboembolism prophylaxis. It may seem annoying to have to fill that out every time, but it makes you think.
Make tasks easier: Reduce task difficulty and ambiguity. We need to train physicians in the proper use of relevant information databases and make these resources available to them. We need to remove as many barriers as possible to good decision making. This may come in the form of evidence-based order sets, clinical decision tools and nomograms, or efficient utilization of evidence-based resources. Bates et al. list “ten commandments” for effective clinical decision support.
Minimize time pressures: Provide sufficient quality time to make decisions. We fall back to System 1 thinking when we are pressed for time, stressed, depressed, under pressure, etc. Hospitals and clinics should promote an atmosphere where appropriate time is given, so that System 2 critical thinking can occur when necessary, without further adding to the stress of a physician who already feels over-worked, under-appreciated, and behind. I won’t hold my breath for that. But clinicians can do this too. Don’t be afraid to tell a patient “I don’t know” or “I’m not sure” and then get back to them after finding the data you need to make a good decision. We should emphasize this idea even on simple decisions. Our snap, instinctive answers are usually correct (especially if we have been packing the parachute well) but we need to always take the time to do something if it is the right thing to do. For example, in education, you might consider always using a form of the One-minute preceptor. This simple tool can turn usually non-educational patient “check-outs” into an educational process for both you and your learner.
Accountability: Establish clear accountability and follow-up for decisions. Physicians too often don’t learn from cases that go wrong. They circle the wagons around themselves and go into an ego-defense mode, blaming the patient, nurses, the resident, or really anyone but themselves. While others may have some part in contributing to what went wrong, you can really only change yourself. We have to keep ourselves honest (and when we don’t, we need honest and not-always-punitive peer review processes to provide feedback). Physicians, unfortunately, often learn little from “bad cases,” or the “crashes,” but they also learn very little from “near-misses.” Usually, for every time a physician has a “crash,” there have been several near-misses (or, as Geroge Carlin called them, “near-hits”). Ideally, we would learn as much from a near-miss as we might from a crash, and, in doing so, hopefully reduce the number of both. We cannot wait for things to go wrong to learn how to improve our processes.
Using personal or institutional databases for self-reflection is one way to be honest about outcomes. I maintain a database of every case or delivery I do; I can use this to compare any number of metrics to national, regional, and institutional averages (like primary cesarean rates, for example). We also need to utilize quality improvement conferences, even in nonacademic settings. Even when things go right, we can still learn and improve.
Feedback: We should provide rapid and reliable feedback so that errors are appreciated, understood, and corrected, allowing calibration of cognition. We need to do this for ourselves, our peers, and our institutions. Peer review processes should use modern tools like root-cause analysis, and utilize evidence-based data to inform the analysis. Information about potential cognitive biases should be returned to physicians with opportunities for improvement. Also, adverse situations and affective disorders that might lead to increased reliance on CDRs should be assessed, including things like substance abuse, sleep deprivation, mood and personality disorders, levels of stress, emotional intelligence, communications skills, etc.
Leo Leonidas has suggested the following “ten commandments” to reduce cognitive errors (I have removed the Thou shalts and modified slightly):
Let’s implement these commandments with some examples:
1. Reflect on how you think and decide.
Case: A patient presents in labor with a history of diet-controlled gestational diabetes. She has been complete and pushing for the last 45 minutes. The experienced nurse taking care of the patient informs you that she is worried about her progress because she believes the baby is large. You and the nurse recall your diabetic patient last week who had a bad shoulder dystocia. You decide to proceed with a cesarean delivery for arrest of descent. You deliver a healthy baby weighing 7 lbs and 14 ounces.
What went wrong?
2. Do not rely on your memory when making decisions.
Case: A patient is admitted with severe preeclampsia at 36 weeks gestation. She also has Type IIB von Willebrand’s disease. Her condition has deteriorated and the consultant cardiologist has diagnosed cardiomyopathy and recommends, among other things, diuresis. You elect to deliver the patient. Worried about hemorrhage, you recall a patient with von Willebrand’s disease from residency, and you order DDAVP. She undergoes a cesarean delivery and develops severe thrombocytopenia and flash pulmonary edema and is transferred to the intensive care unit where she develops ARDS (and dies).
What went wrong?
3. Have an information-friendly work environment.
Case: You’re attending the delivery of a 41 weeks gestation fetus with meconium stained amniotic fluid (MSAF). The experienced nurse offers you a DeLee trap suction. You inform her that based on recent randomized trials, which show no benefit and potential for harm from deep-suctioning for MSAF, you have stopped using the trap suction, and that current neonatal resuscitation guidelines have done away with this step. She becomes angered and questions your competence in front of the patient and tells you that you should ask the Neonatal Nurse Practitioner what she would like for you to do.
What went wrong?
4. Consider other possibilities even though you are sure you are right.
Case: A previously healthy 29 weeks gestation pregnant woman presents with a headache and she is found to have severe hypertension and massive proteinuria. You start magnesium sulfate. Her blood pressure is not controlled after administering the maximum dose of two different antihypertensives. After administration of betamethasone, you proceed with cesarean delivery. After delivery, the newborn develops severe thrombocytopenia and the mother is admitted to the intensive care unit with renal failure. Later, the consultant nephrologist diagnoses the mother with new onset lupus nephritis.
What went wrong?
5. Know Bayesian probability and the epidemiology of the diseases (and tests) in your differential.
Case: A 20 year old woman presents at 32 weeks gestation with a complaint of leakage of fluid. After taking her history, which sounds likes the fluid was urine, you estimate that she has about a 5% chance of having ruptured membranes. You perform a ferning test for ruptured membranes which is 51.4% sensitive and 70.8% specific for ruptured membranes. The test is positive and you admit the patient and treat her with antibiotics and steroids. Two weeks later she has a failed induction leading to a cesarean delivery. At that time, you discover that her membranes were not ruptured.
What went wrong?
6. Rehearse both the common and the serious conditions you expect to see in your speciality.
Case: You are attending the delivery of a patient who has a severe shoulder dystocia. Your labor and delivery unit has recently conducted a simulated drill for managing shoulder dystocia and though the dystocia is difficult, all goes well with an appropriate team response from the entire staff, delivering a healthy newborn. You discover a fourth degree laceration, which you repair, using chromic suture to repair the sphincter. Two months later, she presents with fecal incontinence.
What went wrong?
7. Ask yourself if you are the right person to the make this decision.
Case: Your cousin comes to you for her prenatal care. She was considering a home-birth because she believes that the local hospital has too high a cesarean delivery rate. She says she trusts your judgment. While in labor, she has repetitive late decelerations with minimal to absent variability starting at 8 cm dilation. You are conflicted because you know how important a vaginal delivery is to her. You allow her to continue laboring and two hours later she gives birth to a newborn with Apgars of 1 and 4 and a pH of 6.91. The neonate seizes later that night.
What went wrong?
8. Take time when deciding; resist pressures to work faster than accuracy allows.
Case: A young nurse calls you regarding your post-operative patient’s potassium level. It is 2.7. You don’t routinely deal with potassium replacement. You tell her that you would like to look it up and call her back. She says, “Geez, it’s just potassium. I’m trying to go on my break.” Feeling rushed, you order 2 g of potassium chloride IV over 10 minutes (this is listed in some pocket drug guides!). The patient receives the dose as ordered and suffers cardiac arrest and dies.
What went wrong?
9. Create accountability procedures and follow-up for decisions you have made.
Case: Your hospital quality review committee notes that you have a higher than average cesarean delivery wound infection rate. It is also noted that you are the only member of the department who gives prophylactic antibiotics after delivery of the fetus. You change to administering antibiotics before the case, and see a subsequent decline in wound infection rates.
What went wrong?
10. Use a database for patient problems and decisions to provide a basis for self-improvement.
Case: You track all of your individual surgical and obstetric procedures in a database which records complications and provides statistical feedback. You note that your primary cesarean delivery rate is higher than the community and national averages. Reviewing indications, you note that you have a higher than expected number of arrest of dilation indications. You review current literature on the subject and decide to reassess how you decide if a patient is in active labor (now defining active labor as starting at 6 cm) and you decide to give patients 4 hours rather than 2 hours of no change to define arrest. In the following 6 months, your primary cesarean delivery rate is halved.
What went wrong?
Trowbridge (2008) offers these twelve tips for teaching avoidance of diagnostic errors:
The Differential Diagnosis as a Cognitive Forcing Tool
I believe that the differential diagnosis can be one of our most powerful tools in overcoming bias in the diagnostic process. But the differential diagnosis must be made at the very beginning of a patient encounter to provide mental checks and raise awareness of looming cognitive errors before we are flooded with sources of bias. The more information that is learned about the patient, the more biased we potentially become. The traditional method of making a differential diagnosis is one of forming the differential as the patient’s story unfolds, usually after the history and physical; yet this may lead to multiple cognitive errors. Triage cueing from the patient’s first words may lay the ground work for availability, anchoring, confirmation bias, and premature closure. The most recent and common disease processes will easily be retrieved from our memory, limiting the scope of our thinking merely by their availability.
With bias occurring during the patient interview, by default – through system 1 thinking – we may begin to anchor on the first and most likely diagnosis without full consideration of other possibilities. This causes us to use the interviewing process to seek confirmation of our initial thoughts and it becomes harder to consider alternatives. Scientific inquiry should not seek confirmation of our hypothesis (or our favored diagnosis), but rather proof for rejection of other possibilities. Once we’ve gathered enough data to confirm our initial heuristic thinking, we close in quickly, becoming anchored to our diagnosis. A simple strategy to prevent this course of events is to pause before every patient interview and contemplate the full scope of possibilities; that is, to make the differential diagnosis after learning the chief complaint but before interviewing the patient. By using the chief complaint given on the chart, a full scope of diagnostic possibilities can be considered including the most likely, the most common, the rare and the life threatening. This will help shape the interview with a larger availability of possibilities and encourage history-taking that works to exclude other diagnoses. Here a howardism,
You can’t diagnosis what you don’t think of first.
Having taught hundreds of medical students how to make differential diagnoses, I have always been impressed how easy it is to bias them to exclude even common and likely diagnoses. For example, a patient presents with right lower quadrant pain. The student is biased (because I am a gynecologist), so the differential diagnosis focuses only on gynecologic issues. When taking the history, the student then fails to ask about anorexia, migration of the pain, etc., and fails to consider appendicitis as a likely or even a possible diagnosis. The history and physical was limited because the differential was not broad enough. In these cases, triage cueing becomes devastating.
If bias based merely on my speciality is that profound, imagine what happens when the student opens the door and sees the patient (making assumptions about class, socioeconomic status, drug-dependency, etc.), then hears the patient speak (who narrows the complaint down to her ovary or some other source of self-identified pain), then takes a history too narrowly focused (not asking broad review of system questions, etc.). I have considered lead poisoning as a cause of pelvic/abdominal pain every time I have ever seen a patient with pain, but, alas, I have never diagnosed it nor have I ever tested a patient for it. But I did exclude it as very improbable based on history.
For further reading:
Published Date : August 23, 2016
Categories : Cognitive Bias

(This cartoon and nine more similar ones are here).
Our human reasoning and decision-making processes are inherently flawed. Faced with so many decisions to be made every day, we take short-cuts (called heuristics) that help us make “pretty good” decisions with little effort. These “pretty good” decisions are not always right and often compromise and exchange our best decision for one that is just good enough. These heuristics carry with them assumptions which may not be relevant to the individual decision at hand, and if these assumptions are not accurate for the current problem, then a mistake may be made. We call these assumptions “cognitive biases.” Thus,
When a heuristic fails, it is referred to as a cognitive bias. Cognitive biases, or predispositions to think in a way that leads to failures in judgment, can also be caused by affect and motivation. Prolonged learning in a regular and predictable environment increases the successfulness of heuristics, whereas uncertain and unpredictable environments are a chief cause of heuristic failure (Improving Diagnosis in Healthcare).
More than 40 cognitive biases have been described which specifically affect our reasoning processes in medicine. These biases are more likely to occur with quicker decisions than with slower decisions. The term Dual Process Theory has been used to describe these two distinct ways we make decision. Daniel Kahneman refers to these two processes as System 1 and System 2 thinking.
System 1 thinking is intuitive and largely unintentional; it makes heavy use of heuristics. It is quick and reasoning occurs unconsciously. It is effortless and automatic. It is profoundly influenced by our past experiences, emotions, and memories.
System 2 thinking, on the other hand, is slower and more analytic. System 2 reasoning is conscious and operates with effort and control. It is intentional and rational. It is more influenced by facts, logic, and evidence. System 2 thinking takes work and time, and therefore is too slow to make most of the decisions we need to make in any given day.
A System 1 decision about lunch might be to get a double bacon cheeseburger and a peanut butter milkshake (with onion rings, of course). That was literally the first meal that popped into my head as I started typing, and each of those items resonates with emotional centers in my brain that recall pleasant experiences and pleasant memories. But not everything that resonates is reasonable.
As the System 2 part of my brain takes over, I realize several things: I am overweight and diabetic (certainly won’t help either of those issues); I have to work this afternoon (if I eat that I’ll probably need a nap); etc. You get the idea. My System 2 lunch might be kale with a side of Brussel sprouts. Oh well.
These two ways of thinking actually utilize different parts of our brains; they are distinctly different processes. Because System 1 thinking is so intuitive and so affected by our past experiences, we tend to make most cognitive errors with this type of thought. Failures can occur with System 2 thinking to be sure, and not just due to cognitive biases but also due to logical fallacies, or just bad data; but, overall, System 2 decisions are invariably more correct than System 1 decisions.
We certainly don’t need to overthink every decision. We don’t have enough time to make System 2 decisions about everything that comes our way. Yet, the more we make good System 2 decisions initially, the better our System 1 decisions will become. In other words, we need good heuristics or algorithms, deeply rooted in System 2 cognition, to make the best of our System 1 thoughts. Thus the howardism:
The mind is like a parachute: it works best when properly packed.
The packing is done slowly and purposefully; the cord is pulled automatically and without thinking. If we thoroughly think about where to eat lunch using System 2 thinking, it will have a positive effect on all of our subsequent decisions about lunch.
How does this relate to medicine? We all have cognitive dispositions that may lead us to error.
First, we need to be aware of how we make decisions and how our brains may play tricks on us; a thorough understanding of different cognitive biases can help with this. Second, we need to develop processes or tools that help to de-bias ourselves and/or prevent us from falling into some of the traps that our cognitive biases have laid for us.
Imagine that you are working in a busy ER. A patient presents who tells the triage nurse that she is having right lower quadrant pain; she says that the pain is just like pain she had 6 months ago when she had an ovarian cyst rupture. The triage nurse tells you (the doctor) that she has put the patient in an exam room and that she has pain like her previous ruptured cyst. You laugh, because you have already seen two other women tonight who had ruptured cysts on CT scans. You tell the nurse to go ahead and order a pelvic ultrasound for suspected ovarian cyst before you see her. The ultrasound is performed and reveals a 3.8 cm right ovarian cyst with some evidence of hemorrhage and some free fluid in the pelvis. You quickly examine and talk to the patient, confirm that her suspicious were correct, and send her home with some non-narcotic pain medicine and ask her to follow-up with her gynecologist in the office.
Several hours later, the patient returns, now complaining of more severe pain and bloating. Frustrated and feeling that the patient is upset that she didn’t get narcotics earlier, you immediately consult the gynecologist on-call for evaluation and management of her ovarian cyst. The gynecologist performs a consult and doesn’t believe that there is any evidence of torsion because there is blood flow to the ovary on ultrasound exam. He recommends reassurance and discharge home.
The next day she returns in shock and is thought to have an acute abdomen. She is taken to the OR and discovered to have mesenteric ischemia. She dies post-operatively.
While this example may feel extreme, the mistakes are real and they happen every day.
When the patient told the nurse that her ovary hurt, the nurse was influenced by this framing effect. The patient suffered from triage cueing because of the workflow of the ER. The physician became anchored to the idea of an ovarian cyst early on. He suffered from base-rate neglect when he overestimated the prevalence of painful ovarian cysts. When he thought about his previous patients that night, he committed the gambler’s fallacy and exhibited an availability bias. When the ER doctor decided to get an ultrasound, he was playing the odds or fell victim to Sutton’s slip. When the ultrasound was ordered for “suspected ovarian cyst,” there was diagnosis momentum that transferred to the interpreting radiologist.
When the ultrasound showed an ovarian cyst, the ER physician was affected by confirmation bias. The ER doctor’s frequent over-diagnosis of ovarian cysts was reinforced by feedback sanction. When he stopped looking for other causes of pain because he discovered an ovarian cyst, he had premature closure. When he felt that the patient’s return to the ER was due to her desire for narcotics, the ER doctor made a fundamental attribution error. When he never considered mesenteric ischemia because she did not complain of bloody stools, he exhibited representativeness restraint. When he consulted a gynecologist to treat her cyst rather than explore other possibilities, he was exploited by the sunk costs bias.
Each of these are examples of cognitive biases that affect our reasoning (see definitions below). But what’s another way this story could have played out?
The patient presents to the ER. The nurse tells the doctor that the patient is in an exam room complaining of right lower quadrant pain (she orders no tests or imaging before the patient is evaluated and she uses language that does not make inappropriate inferences). The doctor makes (in his head) a differential diagnosis for a woman with right lower quadrant pain (he does this before talking to the patient). While talking to the patient and performing an exam, he gathers information that he can use to rule out certain things on his differential (or at least decide that they are low probability) and determines the pretest probability for the various diagnoses on his list (this doesn’t have to be precise – for example, he decides that the chance of acute intermittent porphyria is incredibly low and decides not to pursue the diagnosis, at least at first).
After assessing the patient and refining his differential diagnosis, he decides to order some tests that will help him disprove likely and important diagnoses. He is concerned about her nausea and that her pain seems to be out of proportion to the findings on her abdominal exam. He briefly considered mesenteric ischemia but considers it lower probability because she has no risk factors and she has had no bloody stools (he doesn’t exclude it however, because he also realizes that only 16% of patients with mesenteric ischemia present with bloody stools). Her WBC is elevated. He does decide to order a CT scan because he is concerned about appendicitis.
When the CT is not consistent with appendicitis or mesenteric ischemia, he decides to attribute her pain to the ovarian cyst and discharges her home. When the patient returns later with worsened pain, he first reevaluates her carefully and starts out with the assumption that he has likely misdiagnosed her. This time, he notes an absence of bowel sounds, bloating, and increased abdominal pain on exam. He again considers mesenteric ischemia, even though the previous CT scan found no evidence of it, realizing that the negative predictive value of a CT scan for mesenteric ischemia in the absence of a small bowel obstruction is only 95% – meaning that 1 in 20 cases are missed. This time, he consults a general surgeon, who agrees that a more definitive test needs to be performed and a mesenteric angiogram reveals mesenteric ischemia. She is treated with decompression and heparin and makes a full recovery.
These two examples represent an extreme of very poor care to very excellent care. Note that even when excellent care occurred, the rare diagnosis was still initially missed. But the latter physician was not nearly as burdened by cognitive biases as the former physician and the patient is the one who benefits. The latter physician definitely used a lot of System 1 thinking, at least initially, but when it mattered, he slowed down and used System 2 thinking. He also had a thorough understanding of the statistical performance of the tests he ordered and he considered the pre-test and post-test probabilities of the diseases on his differential diagnosis. He is comfortable with uncertainty and he doesn’t think of tests in a binary (positive or negative) sense, but rather as increasing or decreasing the likelihood of the conditions he’s interested in. He used the hypothetico-deductive method of clinical diagnosis, which is rooted in Bayesian inference.
Let’s briefly define the most common cognitive biases which affect clinicians.
I’m sure you can think of many other examples for these biases, and there are many other biases that have been described apart from those on the list. There is an emerging scientific literature which is examining the effects of bias on diagnostic and therapeutic outcomes and on medical error. The 2015 Institute of Medicine Report, Improving Diagnosis in Healthcare, is a good place to start exploring some of the implications of bias in the diagnostic process.
Next we will explore some strategies to mitigate our bias.
Published Date : August 22, 2016
Categories : Evidence Based Medicine

Recently, I made a disparaging comment about data that was not statistically signficant but rather was “trending” toward significance:
There was an apparent “trend” towards fewer cases of CP and less developmental problems. “Trends” are code for “We didn’t find anything but surely it’s not all a waste of time.”
This comment was in reference to the ACTOMgSO4 trial which studied prevention of cerebral palsy using magnesium sulfate. This study is often cited in support of this increasingly common but not evidence-based practice. To be clear, ACTOMgSO4 found the following: total pediatric mortality, cerebral palsy in survivors, and the combined outcome of death plus cerebral palsy were not statistically significantly different in the treatment group versus the placebo group.
Yet, this study is quoted time and time again as evidence supporting the practice of antenatal magnesium. The primary author of the study, Crowther, went on to write one of the most influential meta-analyses on the issue, which used the non-significant subset data from the BEAM Trial to re-envision the non-significant data from the ACTOMgSO4 Trial. Indeed, Rouse, author of the BEAM Trial study, was a co-author of this meta-analysis. If this seems like a conflict of interest, it is. But there is only so much that can be done to try to make a silk purse out of a sow’s ear. These authors keeps claiming that the “trend” is significant (even though the data is not).
Keep in mind that all non-significant data has a “trend,” but the bottom line is it isn’t significant. Any data that is not exactly the same as the comparison data must by definition “trend” away. It means nothing. Imagine that I do a study with 50 people in each arm: in the intervention arm 21 people get better while in the placebo arm only 19 get better. My data is not significantly different. But I really, really believe in my hypothesis, and even though I said before I analyzed my data that a p value of < 0.05 would be used to determine statistical significance, I still would like to get my study published and provide support to my pet idea; so I make one or more of the following “true” conclusions:
All of those statements are true, or are at least half-truths. So is this one:
How did the authors of ACTOMgSO4 try to make a silk purse out of a sow’s ear? They said,
Total pediatric mortality, cerebral palsy in survivors, and combined death or cerebral palsy were less frequent for infants exposed to magnesium sulfate, but none of the differences were statistically significant.
That’s a really, really important ‘but’ at the end of that sentence. Their overall conclusions:
Magnesium sulfate given to women immediately before very preterm birth may improve important pediatric outcomes. No serious harmful effects were seen.
Sounds familiar? It’s definitely a bit of doublespeak. It “may improve” outcomes and it may not. Why write it this way? Bias. The authors knew what they wanted to prove when designing the study, and despite every attempt to do so, they just couldn’t massage the data enough to make a significant p value. Readers are often confused by the careful use of the word ‘may’ in articles; if positive, affirmative data were discovered, the word ‘may’ would be omitted. Consider the non-conditional language in this study’s conclusion:
Although one-step screening was associated with more patients being treated for gestational diabetes, it was not associated with a decrease in large-for-gestational-age or macrosomic neonates but was associated with an increased rate of primary cesarean delivery.
No ifs, ands, or mays about it. But half-truth writing allows others authors to still claim some value in their work while not technically lying. But it is misleading, whether intentionally or unintentionally. Furthermore, it is unnecessary – there is value in the work. The value of the ACTOMgSO4 study was showing that magnesium was not better than placebo in preventing cerebral palsy; but that’s not the outcome the authors were expecting to find – thus the sophistry.
The Probable Error blog has compiled an amazing list of over 500 terms that authors have used to described non-significant p values. Take a glance here; it’s truly extraordinary. The list includes gems like significant tendency (p = o.o9), possibly marginally significant (p = 0.116), not totally significant (p = 0.09), an apparent trend (p = 0.286), not significant in the narrow sense of the word (p = 0.29), and about 500 other Orwellian ways of saying the same thing: NOT SIGNIFICANT.
I certainly won’t pretend that p values are everything; I have made that abundantly clear. We certainly do need to focus on issues like numbers needed to benefit or harm. But we also need to make sure that those numbers are not derived from random chance. We need to use Bayesian inference to decide how probable or improbable a finding actually is. But the culture among scientific authors has crossed over to the absurd, as shown in the list of silly rationalizations noted above. If the designers of a study don’t care about the p value, then don’t publish it; but if they do, then respect it and don’t try to minimize the fact that the study did not disprove the null hypothesis. This type of intellectual dishonesty partly drives the p-hacking and manipulation that is so prevalent today.
If differences between groups in a study are truly important, we should be able to demonstrate differences without relying on faulty and misleading statistical analysis. Such misleading statements would not be allowed in a court of law. In fact, in this court decision which excluded the testimony of the epidemiologist Anick Bérard, who claimed that Zoloft caused birth defects, the Judge stated,
Dr. Bérard testified that, in her view, statistical significance is certainly important within a study, but when drawing conclusions from multiple studies, it is acceptable scientific practice to look at trends across studies, even when the findings are not statistically significant. In support of this proposition, she cited a single source, a textbook by epidemiologist Kenneth Rothman, and testified to an “evolution of the thinking of the importance of statistical significance.” Epidemiology is not a novel form of scientific expertise. However, Dr. Bérard’s reliance on trends in non-statistically significant data to draw conclusions about teratogenicity, rather than on replicated statistically significant findings, is a novel methodology.
These same statistical methods were used in the meta-analyses of magnesium to prevent CP, by combining the non-statistically significant findings of the ACTOMgSO4 study and the PreMAG studies with the findings from the BEAM trial; but, ultimately, not significant means not significant, no matter how it’s twisted.
Published Date : August 18, 2016
Categories : Evidence Based Medicine

If you torture data for long enough, it will confess to anything. – Ronald Harry Coas
Imagine that you’ve just read a study in the prestigious British Medical Journal that concludes the following:
Remote, retroactive intercessory prayer said for a group is associated with a shorter stay in hospital and shorter duration of fever in patients with a bloodstream infection and should be considered for use in clinical practice.
Specifically, the author randomized 3393 patients who had been hospitalized for sepsis up to ten years earlier to two groups: the author prayed for one group and did not pray for the other. He found that the group he prayed for was more likely to have had shorter hospital stays and a shorter duration of fever. Both of these findings were statistically significant, with a p value of 0.01 and 0.04, respectively. So are you currently praying for the patients you hospitalized 10 years ago? If you aren’t, some “evidence-based medicine” practitioners (of the Frequentist school) might conclude that you are a nihilist, choosing to ignore science. But I suspect that even after reading the article, you are probably going to ignore it. But why? How do we know if a study is valid and useful? How can we justify ignoring one article while demanding universal adoption of another, when both have similar p values?
Let’s consider five steps for determining the validity of a study.
1. How good is the study?
Most published studies suffer from significant methodological problems, poor designs, bias, or other problems that may make the study fundamentally flawed. If you haven’t already, please read How to Read A Scientific Paper for a thorough approach to this issue. But if the paper looks like a quality study that made a statistically significant finding, then we must address how likely it is that this discovery is true.
2. What is the probability that the discovered association (or lack of an association) is true?
Of the many things to consider when reading a new study, this is often the hardest question to answer. The majority of published research is wrong; this doesn’t mean, however, that (in most cases) a scientific, evidence-based approach is still not the best way to determine how we should practice medicine. The fact that most published research is wrong is not a reason to embrace anecdotal medicine; almost every anecdotally-derived medical practice has been or will be eventually discredited.
It does mean, though, that we have to do a little more work as a scientific community, and as individual clinicians, to ascertain what the probability of a finding being “true” or not really is. Most papers that report something as “true” or “significant” based on a p value of less than 0.05 are in error. This fact was popularized in 2005 by John Ioannidis, whose paper has inspired countless studies and derivative works analyzing the impact of this assertion. For example,
P-hacking, fraud, retractions, lack of reproducibility, and just honest chance leading to the wrong findings; those are the some of the problems, but what’s the solution? Bayesian inference.
Bayes’ Theorem states:

This equations states that the probability of A given B is equal to the probability of B given A times the probability of A, divided by the probability of B. Don’t be confused. Let’s restate this for how we normally use it in medicine. What we care about is the probability that our hypothesis, H, is true, whatever our hypothesis might be. We test our hypothesis with a test, T; this might be a study, an experiment, or even a lab test. So here we can substitute those terms:
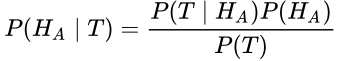
Normally, when we do a test (T), the test result is reported as the probability that the test or study (or the data collected in the study) fits the hypothesis. This is P(T | H). It assumes that the hypothesis is true, and then tells us the probability that the observed data would make our test or study positive (typically taken as a p value < 0.05). But this isn’t helpful to us. I want to know if my hypothesis is true, not just if the data collected and the tests performed line up with what I would expect to see if my hypothesis were true.
Frequentist statistics, the traditionally taught theory of statistics mostly used in biologic sciences, is incapable of answering the question, “How probable is my hypothesis?” Confused by this technical point, most physicians and even many research scientists wrongly assume that when a test or study is positive or “statistically signficant,” that the hypothesis being tested is validated. This misassumption is responsible for the vast majority of the mistakes in science and in the popular interpretation of scientific articles.
Pause…
If Frequentism versus Bayesianism is confusing (I’m sure it probably is), let’s simplify it.
Imagine that you are standing in a room and you hear voices in the next room that sound exactly like Chuck Norris talking to Jean-Claude van Damme. Thrilled, you quickly record the voices. You develop a hypothesis that Chuck and van Damme are in the room next door to you. You use a computer to test whether the voices match known voice samples of the two martial artists. The computer test tells you that the voices are nearly a perfect match, with a p value of < 0.0001. This is what Frequentist statistical methods are good at. This statistical approach tells you the chance that the data you observed would exist if your hypothesis were true. Thus, it tells you the probability of the voice pattern you observed given that the JCVD and Chuck are in the room next door; that is, the probability of the test given the hypothesis, or P(T | H).
But it doesn’t tell you if your hypothesis is true. What we really want to know is the probability that Chuck and the Muscles from Brussels are in the room next door, given the voices you have heard; that is, the probability of the hypothesis given the test, or P(H | T). This is the power of Bayesian inference, because it allows us to consider other information that is beyond the scope of the test, like the probability that the two men would be in the room in the first place compared to the probability that the TV is just showing a rerun of The Expendables 2.
Bayes tells us the probability of an event based on everything we know that might be related to that event, and it is updated as new knowledge is acquired.
Frequentism tells us the probability of an event based on the limit of its frequency in a test. It does not allow for the introduction of prior knowledge or future knowledge.
Our brains naturally work using Bayesian-like logic so it should come naturally.
Resume…
So we need Bayes to answer the question of how probable our hypothesis actually is. More specifically, Bayesian inference allows us to change our impression of how likely something is based on new data. So, at the start, we assume that a hypothesis has a certain probability of being true; then, we learn new information, usually from experiments or studies; then, we update our understanding of how likely the thing is to be true based on this new data. This is called Bayesian Updating. As I said, the good news is, you are already good at this. Our brains are Bayesian machines that continuously learn new information and update our understanding based on what we learn. This is the same process we are supposed to be using to interpret medical tests, but in the case of a scientific study, instead of deciding if a patient has a disease by doing a test, we must decide if a hypothesis is “true” (at least highly probable) based on an experimental study.
Let’s see how Bayesian inference helps us determine the true rates of Type I and Type II errors in a study.
Type I and Type II Errors
Scientific studies use statistical methods to test a hypothesis. If the study falsely rejects the null hypothesis (that there is no association between the two variables), then that is called a Type I Error, or a false positive (since it incorrectly lends credence to the alternative hypothesis). If there is an association that is not detected, then this is called a Type II Error, or false negative (since it incorrectly discounts the alternative hypothesis).
We generally accept that it’s okay to be falsely positive about 5% of the time in the biological sciences (Type 1 Error). This rate is determined by alpha, usually set to 0.05; this is why we generally say that anything with a p value < 0.05 is significant. In other words, we are saying that it is okay to believe a lie 5% of the time.
The “power” of a study determines how many false negatives there will be. A study may not have been sufficiently “powered” to find something that was actually there (Type II Error). Power is defined as 1 – beta; most of the time, beta is 0.2, and this would mean that a study is likely to find 80% of true associations that exist. In other words, we miss something we wanted to find 20% of the time.
In order for the p value to work as intended, the study must be powered correctly. Too few or too many patients in the study creates a problem. So a power analysis should performed before a study is conducted to make sure that the number of enrolled subjects (the n) is correct.
Most people who have taken an elementary statistics course understand these basic principles and most studies at least attempt to follow these rules. However, there is a big part still missing: not all hypotheses that we can test are equally likely, and that matters.
For example compare these two hypotheses: ‘Cigarette smoking is associated with development of lung cancer’ versus ‘Listening to Elvis Presley music is associated with development of brain tumors.’ Which of these two hypotheses seems to be more likely, based on what we already know, either from prior studies on the subject or studies related to similar subject matter? Or if there are no studies, based on any knowledge we have, including our knowledge of basic sciences?
We need to understand the pre-study probability that the hypothesis is true in order to understand how the study itself affects the post-study probability. This is the same skill set we use when we interpret clinical tests: the test is used to modulate our assigned pretest probability and to generate a new posttest probability (what Bayesians call the posterior probability). So, too, a significant finding (or lack of a significant finding) is used to modulate the post-study probability that a particular hypothesis is true or not true.
Let’s say that we create a well-designed study to test our two hypotheses (the cigarette hypothesis and the Elvis hypothesis). It is most likely that the cigarette hypothesis will show a positive link and the Elvis hypothesis will not. But what if the cigarette hypothesis doesn’t find a link for some reason? Or the Elvis hypothesis does show a positive link? Do we allow these two studies to upend and overturn everything we currently know about the subjects? Not if we use Bayesian inference.
I’m not sure what the pre-study probabilities that these two hypothesis are true should be, but I would guess that there is a 99% chance, based on everything we know, that cigarette smoking causes lung cancer, and about a 1% chance that listening to Elvis causes brain tumors. Let’s see what this means in real life.
We can actually calculate how these pre-study probabilities affect our study, and how our study affects our assumptions that the hypotheses are true. Assuming a p value of 0.05 and a beta of 0.10, the positive predicative value (PPV or post-study probability) that the cigarette hypothesis is true (assuming that our study found a p value of less than 0.05) is 99.94%. On the other hand, the PPV of the Elvis hypothesis, with same conditions, is only 15.38%. These probabilities assume that the studies were done correctly and that the resultant findings were not manipulated in any way. If we were to introduce some bias into the Elvis study (referred to as u), then the results change dramatically. For example, with u=0.3 (the author never did like Elvis anyway), the PPV becomes only 2.73%.

Bias comes in many forms and affects many parts of the production sequence of a scientific study, from design, implementation, analysis, and publication (or lack of publication). It is not always intentional on the part of the authors. Remember, intentionally or not, when people design studies, they often design the study in a way to show the effect they are expecting to find, rather than to disprove the effect (which is the more scientifically rigorous approach).
We might also conduct the same study over and over again until we get the finding we want (or more commonly, a study may be repeated by different groups with only one or two finding a positive association – knowing how many times a study is repeated is difficult since most negative studies are not published). If the Elvis study were repeated 5 times (assuming that there was no bias at all), then the PPV of a study showing an association would only be 4.27% (and add a bit of bias and that number drops dramatically, well below 1%). Note that these probabilities represent a really well done study, with 90% power. Most studies are underpowered, with estimates ranging in the 20-40% range, allowing for a lot more Type II errors.

And remember, this type of analysis only applies to studies which found a legitimately significant p value, with no fraud or p-hacking or other issues.
What if our cigarette study didn’t show a positive result? What is the chance that a Type II error occurred? Well the negative predictive value (NPV) would be only 8.76% leaving a 91.24% chance that a Type II error occurred (a false negative), assuming that the study was adequately powered. If the power were only 30% (remember that the majority of studies are thought to be under-powered, in the 20-40% range), then the chance of a Type II Error would be 98.65%. Conversely, if the Elvis study says that Elvis doesn’t cause brain tumors, its negative predictive value would be 99.89%.
Thus, the real risk of a Type I or Type II error is dependent on study design (the alpha and beta boundaries), but it is also dependent upon the pretest probability of the hypothesis being tested.
Two more examples. First, let’s apply this first step to the previously mentioned retrospective prayer study. The author used a p value of 0.05 as a cut off for statistical significance and there was no power analysis, so we might assume the study was under-powered, with a beta of 0.5. We might also assume significant bias in the construction of the study (u=0.5). Lastly, how likely do we think that prayer 10 years in the future will affect present-day outcomes? Let’s pretend that this has a 1% chance of being true based on available data. We find that the positive predictive value of this study is only 1.42%, if our bias assumption is correct, and no better than 9.17% if there were no bias, p-hacking, or other manipulations of any kind.
When you read about this study, you knew already in your gut what Bayes tells you clearly: There is an incredibly low chance, despite a well-designed and clinically significant trial, published in a prestigious journal, that the hypothesis is much more likely than the 1% probability we guessed in the first place. Note that it is slightly more likely than your pretest probability, but still so unlikely that we should not change our practices, as the author suggested.
We can use as a second example the BEAM Trial. Recall that this trial is the basis of using magnesium for prevention of cerebral palsy. We previously demonstrated that the findings of the trial were not statistically significant in the first place and are the result of p-hacking; but what if the results had been significant? Let’s do the analysis. We know that the p value used to claim significance for reduction of non-anomalous babies was p = 0.0491, so we can use this actual number in the calculations. The power of the trial was supposed to be 80% but the “significant” finding came in an underpowered subset analysis, so will set beta equal to 0.6. There were four previous studies which found no significant effect, so we will consider 5 studies in the field. Bias is a subjective determination, but the bias of the authors is clearly present and the p-hacking reinforces this. We will set bias to 0.4. Lastly we must consider what the probability of the hypothesis was prior to the study. Since four prior studies had been done which concluded no effect, the probability that the alternative hypothesis was true must be considered low prior to the trial; in fact, prior data had uniformly suggested increased neonatal death. Let’s be generous and say that it was 10%. What do we get?

Since this was the fifth study (with the other four showing no effect), then the best post-study probability is 17.91%; that number doesn’t discount for bias. Incorporating the likely bias of the trial would push the PPV even lower, to about 3%. Of course, all of that assumes that the trial had a statistically significant finding in the first place (it did not). The negative predictive value, then, is the most precise number, which stands at 96.79%.
Either way, it is probably safe to say that as the data stands today, there is only about a ~3% chance that magnesium is associated with a reduced risk of CP in surviving preterm infants. Recall that Bayesian inference allows us to continually revise our estimate of the probability of the hypothesis based on new data. Since BEAM was published, two additional long-term follow-up studies of children exposed to antenatal magnesium have been published which showed no neurological benefit from the exposure in school-aged children. With Bayesian updating, we can use this data to further refine the probability that magnesium reduces the risk of cerebral palsy. If the estimate was ~3% after the BEAM Trial, it is now significantly lower based on this new information.
While we are discussing magnesium, how about its use as a tocolytic? Hundreds of studies have shown that it is ineffective, with at least 16 RCTs. What if a well-designed study were published tomorrow that showed a statistically-significant effect in reducing preterm labor? How would that change our understanding? With the overwhelming number of studies and meta-analyses that have failed to show an effect, let’s set the pre-study probability to about 1%:

So just counting the RCT evidence against magnesium as a tocolytic, a perfectly designed, unbiased study would have no more than a 1.71% positive predictive value. A potential PPV so low means that such a study should not take place (though people continue to publish and research in this dead-end field). Bayesian inferences tells us that the belief that magnesium may work as a tocolytic or to prevent cerebral palsy has roughly the same evidence as the idea that remote intercessory prayer makes hospital stays of ten years ago shorter.
Here’s the general concept. Let’s graphically compare a high probability hypothesis (50%) to a low probability one (5%), using both an average test (lower power with questionable p values or bias) and a really good study (significant p value and well-powered).
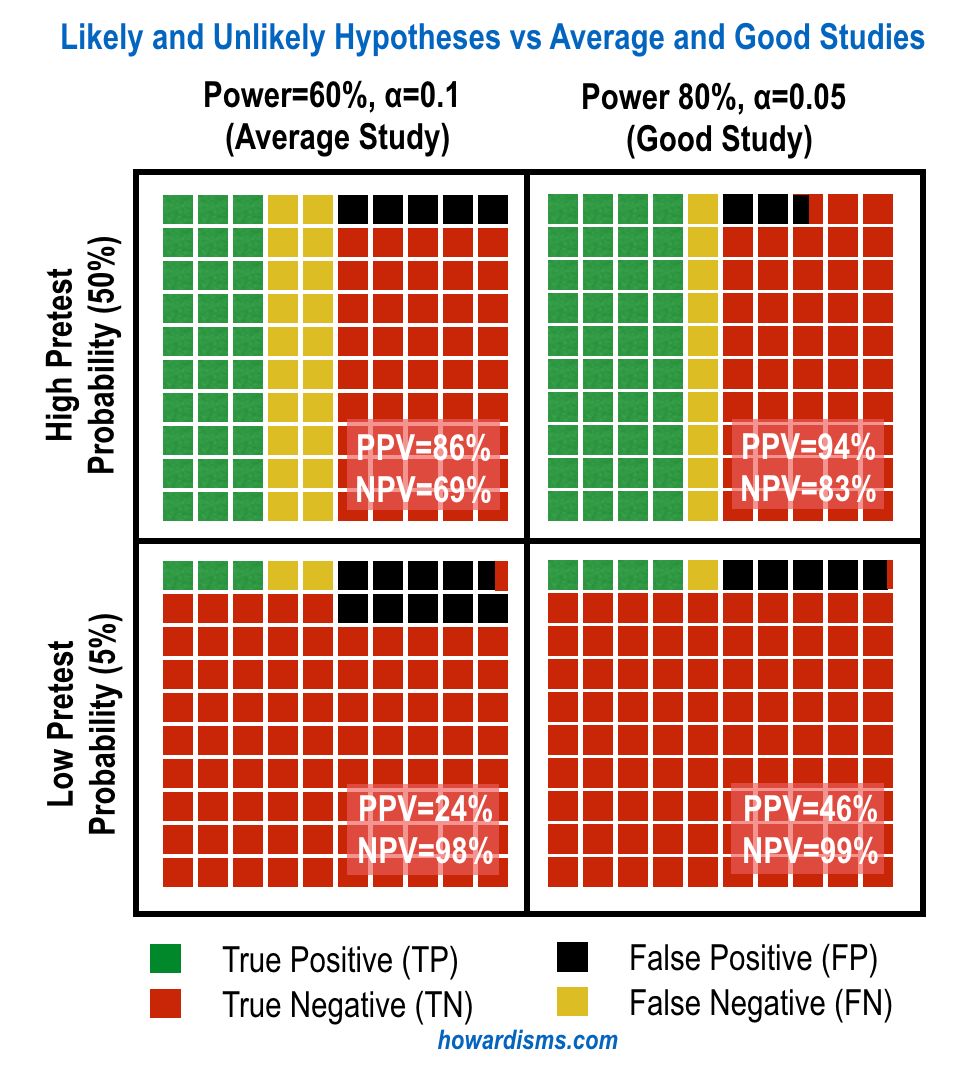
Take a look at the positive and negative predictive values; they are clearly influenced by the likelihood of the hypothesis. Many tested hypotheses are nowhere near as likely as 5%; the hypotheses of most epidemiological studies and other “data-mining” type studies may carry more like a 1 in 1,000 or even 1 in 10,000 odds.
3. Rejecting the Null Hypothesis Does Not Prove the Alternate Hypothesis
The casual view of the P value as posterior probability of the truth of the null hypothesis is false and not even close to valid under any reasonable model, yet this misunderstanding persists even in high-stakes settings. – Andrew Gellman
When the null hypothesis is rejected (in other words, when the p value is less than 0.05), that does not mean that THE alternative hypothesis is automatically accepted or that it is even probable. It means that AN alternative hypothesis is probable. But the alternative hypothesis espoused by the authors may not be the best (and therefore most probable) alternative hypothesis. For example, I may hypothesize that ice cream causes polio. This was a widely held belief in the 1940s. If I design a study in which the null hypothesis is that the incidence of polio is not correlated to the incidence of ice cream sales, and then I find that it is, then I reject the null hypothesis. But this does not then mean that ice cream causes polio. That is one of many alternative hypotheses and much more data is necessary to establish that any given alternative hypothesis is probable.
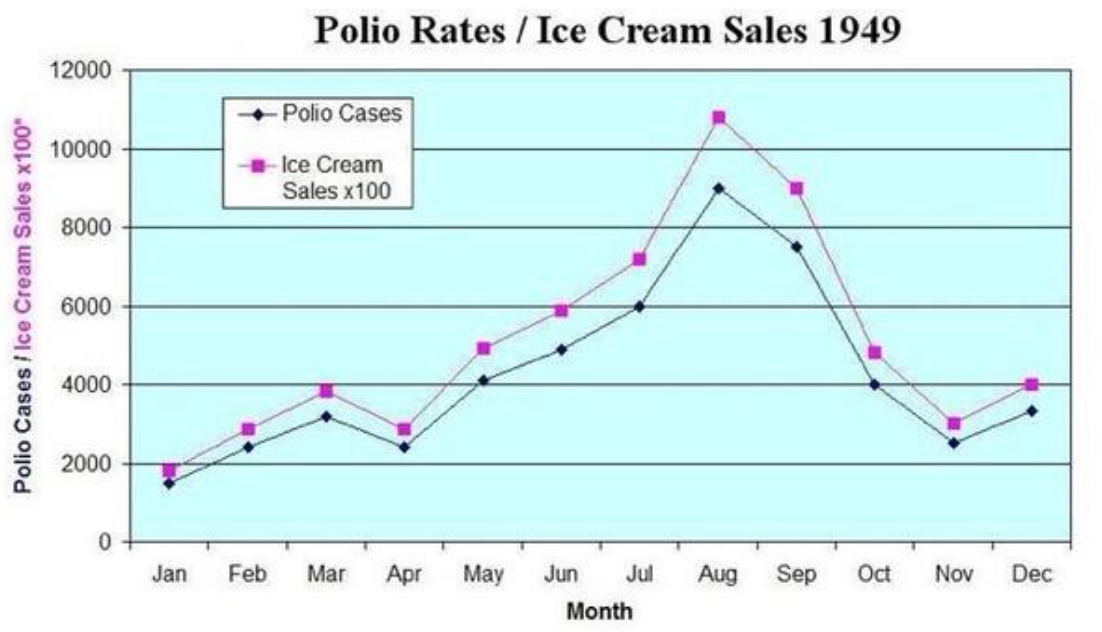
This is a mistake of “correlation equals causation” and this is the most likely mistake with this type of data. I’m fairly sure that organic foods do not cause autism though the two are strongly correlated (but admittedly, I could be wrong):

A study published just this week revealed a correlation between antenatal Tylenol use and subsequent behavioral problems in children. Aside from the fact that this was a poorly controlled, retrospective, epidemiological study (with almost no statistical relevance and incredibly weak pretest probability), even if it were better designed and did indeed determine that the two factors were significantly correlated, it still would be no more evidence that Tylenol causes behavioral problems in children than the above data is evidence that organic food causes autism. There are a myriad of explanations for the correlation. Perhaps mothers who have more headaches raise children with more behavioral problems? Or children with behavioral problems cause their mothers to have more headaches in their subsequent pregnancies? Correlation usually does not equal causation.
But if a legitimate finding were discovered, and it appears likely that it is causative, we must next assess how big the observed effect is.
4. Is the magnitude of the discovered effect clinically significant?
There are an almost endless number of discoveries that are highly statistically significant and probable, but they fail to be clinically significant because the magnitude of the effect is so little. We must distinguish between what is significant and what is important. In other words, we may accept the hypothesis after these first steps of our analysis, but still decide not to make use of the intervention in our practice.
I will briefly mention again a previous example: while it is likely true that using a statin drug may reduce a particular patient’s risk of a non-fatal MI by 1%age point over ten years, is this intervention worth the $4.5M it costs to do so (let alone all of the side effects of the drug)? I’ll let you (and your patient) decide. Here is a well-written article explaining many of these concepts with better examples. I will steal an example from the author. He says that saying that a study is “significant” is sometimes like bragging about winning the lottery when you only won $25. “Significant” is a term used by Frequentists whenever the observed data is below the designated p value, but that doesn’t mean that observed association really means anything in practical terms.
5. What cost is there for adopting the intervention into routine practice?
Cost comes in two forms, economic and noneconomic. The $4.5M cost of preventing one nonfatal MI in ten years is likely not to be considered cost-effective by any honest person. But noneconomic costs come in the form of unintended consequences, whether physical or psychological. Would, for example, an intervention that decreased the size of newborns by 3 ounces in mothers with gestational diabetes be worth implementation? Well, maybe. That 3 ounces might, over many thousands of women, save a few shoulder dystocias or cesareans. So if it were free, and had no significant unintended consequences, then yes it probably would be worth it. But few interventions are free and virtually none don’t expose the patients to unintended harms. So the cost must be worth the benefit.
Studies do not always account for all of the costs, intended and unintended. So often the burden of considering the costs of implementation fall upon the reader of the study. Ultimately, deciding whether to use any intervention is a shared decision between physician and patient and one which respects the values of the patient. The patient must be fully informed, understanding precisely both the risks and the benefits in terms she can understand.
Was Twain Right?
Many are so overwhelmed by the seemingly endless problems with scientific papers that the Twain comment of “Lies, Damned Lies, and Statistics” becomes almost an excuse to abandon science-based medicine and return to the dark ages of anecdotal medicine. Most physicians have been frustrated by some study that feels wrong but they can’t explain why it’s wrong, as the authors shout about their significant p value.
But Twain’s quote should be restated: There are lies, damned lies, and Frequentism. The scientific process is saved by Bayesian inference and probabilistic reasoning. Bayes makes no claim as to what is true or not true, only to what is more probable or less probable; Bayesian inference allows us to quantify this probability in a useful manner. Bayes allows us to consider all evidence, as it comes, and constantly refine how confident we are about what believe to be true. Imagine if rather than reporting p values, scientific papers concluded with an assessment of how probable the reported hypotheses are. This knowledge could be used to directly inform future studies and draw a contrast between Cigarettes and Elvis. But for now we must begin to do this work ourselves.
Criticisms
Why are Frequentists so resistant to Bayesian inference? We will discuss this in later posts; but, suffice it to say, it is mostly because there seems to be a lot of guessing about the information used to make these calculations. I don’t really know how likely it is that listening to Elvis causes brain cancer. I said 1% but, of course, it is probably more like 1 in a billion. This uncertainty bothers a lot of statisticians, so they don’t want to use a system that is dependent on so much uncertainty. Many statisticians are working on methods of improving the processes for making these calculations, which will hopefully make our guesses more and more accurate.
Yet, the fact remains that the statistical methods that Frequentists want to adhere to just cannot provide any type of answer to the question, Does listening to Elvis cause brain cancer? So even a poor answer is better than no answer. I have patients to treat and I need to do the best I can today. Still, when trying to determine the probability of the Elvis hypothesis, I erred on the side of caution; by estimating even a 1% probability of this hypothesis, I remained open-minded. But even then, my study only said that there was a tiny chance that it did. If I’m worried about it, I can repeat the study a few times or power it better and get an even lower posterior probability. I am not though, so Don’t Be Cruel.
Oh, also remember this: the father of Frequentism, Fisher, pervertedly used his statistical methods to argue that cigarette smoking did not cause lung cancer – a fact that had been established by Bayesian inference.
Equations
Don’t keep reading below unless you really care about the math…
Power is defined as the probability of finding a true relationship, it it exists:
![]()
Similarly, the probability of claiming a false relationship is bound by alpha, which is the threshold that authors select for statistical significance, usually 0.05:
![]()
Recall the formula for determining the positive predictive value (PPV) is:
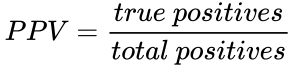
First, we need to determine how many true positives occur, and how many total positives occur. We must consider R, which is the ratio of true relationships to false relationships:
![]()
This can be based upon generalizations of the particular research field (such as genomics, epidemiology, etc.) or specific information already known about the hypothesis from previous evidence. This R ratio is the basis of the prior probability, that is, the probability that the alternative hypothesis is true: ![]()
This prior probability is calculated according to the formula,
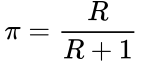
We can therefore express the PPV either in terms of R:
![]() Or we can express the PPV in terms of π (see here for source):
Or we can express the PPV in terms of π (see here for source):
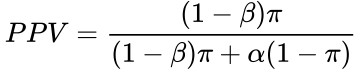
If a coefficient of bias is considered, the equation becomes (see here for derivation):
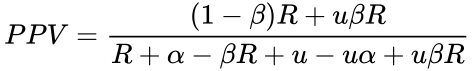
Selecting for the degree of bias is usually subjective, unless methods are used for estimating bias in particular fields or for particular subjects (the prevailing bias). If there have been multiple, independent studies performed, where n is the number of independent studies, not accounting for any bias, the equation becomes: 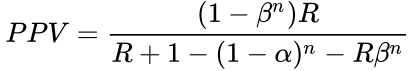 The False Positive Report Probability (FPRP) can be calculated simply as 1–PPV, or directly in the simple case in terms of π as:
The False Positive Report Probability (FPRP) can be calculated simply as 1–PPV, or directly in the simple case in terms of π as:

Published Date : August 13, 2016
Categories : Cognitive Bias, Evidence Based Medicine, OB/Gyn
 How did our profession get so far down the wrong track regarding magnesium? Why is it today that most women in preterm labor are still exposed to magnesium sulfate, either as a tocolytic or to prevent cerebral palsy or both? If you have read the three part series on magnesium, you’re either asking yourself these questions or you have convinced yourself that I have not provided some part of the data or fully explained the issues. It is hard to believe that we all, like those lemmings, have marched off the wrong cliff. If you think that something is missing in my presentation, please send it to me as soon as you find it.
How did our profession get so far down the wrong track regarding magnesium? Why is it today that most women in preterm labor are still exposed to magnesium sulfate, either as a tocolytic or to prevent cerebral palsy or both? If you have read the three part series on magnesium, you’re either asking yourself these questions or you have convinced yourself that I have not provided some part of the data or fully explained the issues. It is hard to believe that we all, like those lemmings, have marched off the wrong cliff. If you think that something is missing in my presentation, please send it to me as soon as you find it.
About 10 years ago, I presented an exhaustive one hour presentation on the data regarding magnesium as a tocolytic. The audience, at an ACOG conference, was similarly forced to make a decision by the overwhelming nature of the data presented. Several older physicians came up to me and said, “I’m just sure there was another paper you missed that said that mag works for 48 hours.” Of course, there wasn’t; but that idea had been so often repeated that these physicians assumed it must have a source. Some told me of the Canadian Ritodrine Study and how it found that tocolytics, or at least ritodrine, was shown to be effective versus placebo at preventing delivery within 48 hours, allowing time to administer steroids. The study did not find that, but I was able to find where the study had been misquoted to say so in a review article, and then the review article that made the mistake was used as a source of other articles. Our cognitive biases lead us to stop asking questions once we find what appears to be support for our practices or beliefs. This is called search satisfying or confirmation bias.
On another occasion, a medical student (who today is a very wonderful OB/GYN) challenged my assertion that magnesium was an ineffective tocolytic by bringing me a summary of a then recent meta-analysis of the available placebo-controlled, randomized trials, which concluded that “magnesium was an effective tocolytic agent.” The short summary, printed in the ACOG Clinical Review newsletter, should have read “magnesium was not an effective tocolytic agent.” Once we downloaded the paper that had been referred to in the review, the typographical mistake was obvious and I was redeemed in his eyes. How did this even happen? I am sure that the editor of the newsletter was so accustomed to using magnesium as a tocolytic that the typo didn’t even register as such in his head. Nor did this seem unusual to the student or many thousands of other readers since they too were used to seeing magnesium used as a tocolytic on a daily basis.
I, on the other hand, lucked out because I had read most of the sixteen or so trials that were reviewed in the meta-analysis, so I knew that something didn’t quite make sense. This was the stimulus to check the primary source.
Lesson #1: Always check the primary sources.
Honest mistakes happen and dishonest mistakes happen. Don’t be lead astray by either. Most of the literature is regurgitation of older literature through commentaries, reviews, and meta-analyses. Textbook authorship is similarly biased. Most texts start with a review of what the author or authors actually do in practice, then a literature search is assembled to provide footnotes for each of these points to validate the protocol. Since a literature search can provide positive support for almost any practice, including suboccipital trephining, then this common authorship practice is dependent upon the author being “right” in the first place. So always check the primary sources, and what’s more, do an exhaustive literature review to see if that primary source is an outlier or if it is consistent with what we have generally found about the subject. Today, suboccipital trephining is the outlier, but if you were willing to rely on just a few poorly designed papers from the past, I can convince you that it is the right thing to do.
Lesson #2: Always consider the full body of evidence.
Scientific consensus is both a good and a bad thing. It is a good thing when it is based upon a consensus of well-designed, validated, and replicated scientific studies. It is a bad thing when it merely represents common practice or popular opinion. The literature-based scientific consensus has always been that magnesium is an ineffective tocolytic and it does not reduce the risk of cerebral palsy in surviving low birth weight infants. But the popular opinion-based scientific consensus has varied widely on both issues throughout the years.
Popular opinion and common practice often are not rooted in science. David Grimes, in the previously mentioned Green Journal editorial, said that magnesium tocolysis “reflects inadequate progress toward rational therapeutics in obstetrics.” That was a kind way of saying that its popular and widespread use was irrational given the scientific literature available on the subject. History has taught us that most widely held scientific beliefs are eventually overturned in the generations to come. Each generation who believed things like the geocentric theory of planetary motion did so based on what they considered to be highly rational evidence; the average person, even the average scientist, believed it because someone whom they assumed was smarter than them told them that it was true. We make the same mistakes today.
Lesson #3: Real scientific consensus is based on the agreement of well-designed, validated, and replicated scientific studies, not opinions or common practice
We far too often defer to those powerful personalities whom we assume to be experts in their areas of interest. Certainly, a person who has spent his whole career, or at least a large portion of it, researching and studying one particular area of science should be and is given a forum for expressing what they have learned. Nevertheless, their opinions and ideas should not be given carte blanche. How many of Sigmund Freud’s absurd and ridiculous theories do we still believe today? Why was he ever allowed to opine, for example, that cerebral palsy was caused by Obstetricians?
Since personal bias and the pressures and demands of career-dependent scientific investigation are such large motivators for things like scientific fraud, P-hacking, biased design of studies, and self-promoting interpretation of data, then often those who should have the most to offer are also those who have the most reason and motivation to be consciously or unconsciously dishonest about the available data. This is unconscious dishonesty is what we call cognitive bias. Even though the average practicing obstetrician may not have a particular set of cognitive biases that would lead her to misinterpret a particular set of data, if she chooses to endow with too much authority the opinions of certain so-called “thought leaders,” then she takes on defaults and the faulty conclusions of those cognitive biases. Sometimes the Emperor has no clothes, and the last person to realize this is the Emperor.
Lesson #4: Don’t overly rely upon the opinion of experts, particularly when those experts have a career at stake based upon the promulgation of their pet theories.
Far too often, what should be a strength (deep immersion in a narrow field of knowledge) becomes a weakness (a lack of context and dogmatic beliefs that activate cognitive biases). This is what is meant by the expression, He can’t see the forest for the trees. Stop assuming that an expert on a single oak tree is at the same time an expert on the entire biodiversity of the forest. Not only does he sometimes lose sight of how the whole forest must work together, but often times he will be so passionate about preserving the one oak tree that he will destroy the forest.
Subspecialists sometimes value too much their areas of interest; and an outcome or value that they may hold as important may not be as important to others who have a stake. Everything we do has both potential risks and potential benefits. Balancing these risks, while respecting the values of our patients, is the art of clinical medicine. Much harm and error is brought about when we over-value certain benefits and under-appreciate certain risks. The blinders worn by those who are too deep in the forest is often the cause for this form of cognitive bias.
Who should best make our guideline for screening for cervical cancer, a general gynecologist or a gynecologic oncologist? Perhaps the correct answer is both. But the gynecologic oncologist, having too often seen the horror stories of undiagnosed and advanced cervical cancer, and having perhaps never seen the harms afforded by false positive diagnoses and overtreatment of cancer precursors, is too biased to go it alone in designing such a guideline. Infants in the BEAM Trial were over 4 times as likely to die as they were to survive with moderate or severe cerebral palsy. The larger number of perinatal deaths can easily absorb an excess 10 or so deaths without appearing to see statistical significance; at the same time, a similar change in the number of survivors with cerebral palsy will make that statistical category appear to change in a statistically significant way. If the only thing you care about is decreasing the number of survivors with cerebral palsy, then given enough attempts you will be able to design a study that makes this appear to be true. But we have to consider all outcomes, and we have to appreciate the absolute risk reduction or risk increase associated with our decisions.
Lesson #5: Don’t myopically consider just one outcome or even a handful of outcomes; consider all outcomes, including unexpected and unintended consequences.
While routine mammography in the sixth decade of life decreases the risk of death from breast cancer by 20%, it does not decrease the risk of death from cancer. Be careful to choose the outcomes that matter. I recently saw a patient who was taking a statin drug for elevated cholesterol. She was an otherwise healthy woman with no cardiovascular risk factors. We used a risk and benefits calculation tool from the Mayo Clinic website to determine the real value of her continuing to take this drug for the next 10 years.

It turns out that if she takes the drug every day for the next 10 years, given her other risk factors and health indicators, she would reduce her risk of having a nonfatal myocardial infarction by one percentage point in the next decade. She had been having some side effects with the medication and her primary care physician was adamant that she not stop it. She, of course, had no idea that the continuous and daily usage of this medication afforded her so little benefit over 10 years.
The particular drug, by the way, costs $270 per month (Crestor). Invested at a 6% interest rate, this represents lost savings of $45,268.11 over that same ten year period. Since there was only a one percentage point reduction in her risk of a nonfatal MI, then a total of $4,526,811 would be spent to prevent one nonfatal MI. Yes, that’s right, just 100 patients! – the typical primary care doctor probably has a 1000 patients like this his practice. That $45M over a ten year period per primary care doctor is why medical care costs so much in the US and why we get free lunches from drug reps.
If all you care about is reducing the risk of heart attacks, then you will advocate for using this drug. That single nonfatal MI is your oak tree. While the statement, “Taking this medicine will reduce your risk of a heart attack” is true, it really does not tell the whole story. We have to appreciate how much risk reduction occurs and at what cost. Most patients would rather have the money spent on that drug to help their children or grandchildren get an education than to reduce their risk of a nonfatal MI by one percentage point. For the cost of preventing one nonfatal MI, we could’ve paid for 150,000 flu shots (at $30 per shot), preventing about 4,500 cases of the flu, some of which would have been fatal.
Lesson #6: Express the real risks and benefits of what we do in absolute terms, so that both we and the patients truly understand them.
Of course, this last point assumes that there are any statistically significant benefits from treating preterm labor with magnesium sulfate; there are not. In the case of performing routine mammography on low risk women or using statin medications for isolated hyperlipidemia, there are statistically significant potential benefits; yet, we must frame them and explain them to our patients in terms that realistically express the potential benefits, not paternalistically invoke our will upon the patients.
Clear benefits are easy to see in studies and they are easy to explain to patients. We may argue about how valuable a flu shot is to certain populations, but it is clear that flu shots are relatively low risk and prevent many people from succumbing to the flu. I don’t need to P-hack the data or perform a meta-analysis of nonsignificant studies to try to make this point. This is all the more important when there are multiple explanations for a given set of data or multiple confounders that influence the data. Studies of neurological outcomes of very low birth weight babies are confounded by literally hundreds of variables. Beyond obvious variables like gestational age at time of delivery, race, gender, circumstances leading up to early delivery, health status of the mother, mode of delivery, completion of antenatal steroids, and other similar factors, there are hundreds of other influential factors that we cannot account for easily, like location of delivery, genetics of the parents, quality of care provided by staff who were on call that day, quality of care in the NICU, variation in local interpretation of diagnostic parameters for things like head ultrasounds or neurodevelopmental assessment tools, etc.
It is probable that even things like time of day of delivery (perhaps a measure of the readiness of the in NICU staff) has more to do with subsequent neurodevelopmental outcomes of very low birth weight babies than does the mother receiving 4 g of magnesium sulfate, only a small fraction of which even crossed over to affect the fetus in the first place. Dare I call this common sense? But since neither the initial data of the PreMAG study nor the school-age follow-up data showed any statistically significant differences in the children exposed to 4 g magnesium versus the children who were not exposed, then this is more than just common sense, it is supported by scientific data.
Lesson #7: Real outcomes are really obvious in studies, and they are not dependent upon controversial statistical methodologies or P-hacking.
Cigarette smoking clearly is related to adverse outcomes, even though the father of Frequentist statistics tried his best to prove otherwise. This fact is not difficult to show and it is demonstrated time and time again in a multitude of studies conducted in a multitude of ways with a multitude of outcomes. It’s a real outcome and it is really obvious.
Still, the biggest reason why magnesium has and continues to be a source of silliness in obstetrics is because we physicians refuse to think critically and scientifically. We should always first seek to disprove any hypothesis or theory. If a scientific study, designed well and honestly executed, were to show some benefit to children of maternal exposure to magnesium sulfate, despite the investigators’ very best efforts to disprove such an unnatural assumption, then we might be onto something.
On the other hand, when the name of the trial is ‘Beneficial Effects of Antenatal Magnesium,’ we are hard-pressed to question how diligently the authors worked to disprove this hypothesis. Even if the data suggested some potential benefit, this does not mean that the alternative hypothesis is true. In other words, if the null hypothesis were that antenatal magnesium provided no neurological benefits to children, then finding data that suggests that the null hypothesis is not true does not instead mean that the alternative hypothesis is true. This is one of the great faults of the producers of scientific literature; they often draw conclusions from the data that the data itself does not actually support. What other alternative explanations are also compatible with the data? Usually there are many.
Lesson #8: Always seek to disprove your hypothesis or theory, and always consider alternative hypotheses that fit the data.
Too often today in arguments, we hear appeals to Science, as if science were positioned to prove (or disprove) anything. When you hear people say things like, “That study disproved that theory,” or, “Science has proven that…,” you are hearing an abuse of what science is and what it offers to our knowledge. Similarly, when you hear people invoke the “Scientific consensus,” or when you hear people make statements that carry a degree of certitude about anything, like, “We know such and such based on such and such,” you may be hearing people who have fallen prey to the cult of scientism. This type of reductionist philosophy oversimplifies very complex problems and claims powers for science that science itself does not claim. Science is not capable of determining all truth and knowledge. It is, however, able to conclude that some things are more or less likely than others. We do not prove or disprove anything. We simply know that some ideas or explanations are more probable than others. This probabilistic worldview is a corollary of Bayesian reasoning or plausible inference. It embraces uncertainty and rejects dogma. It favors complexity and rejects reductionism.
Lesson #9: Approach every question critically; seek to disprove hypotheses; embrace uncertainty; consider how likely a thing is based on all available evidence.
Published Date : August 12, 2016
Categories : Evidence Based Medicine, OB/Gyn

In Part 1, we learned about magnesium’s role in treating and preventing eclampsia. In Part 2, we discussed the mistakes made in using it as a tocolytic; its efficacy as a tocolytic was thoroughly refuted by the early 2000s. By 2008, no credible physician could justify the use of magnesium sulfate for the treatment of preterm labor with anything more than anecdotal stories. This did not, however, mean that obstetricians stopped using it. To the contrary: while many younger docs began using nifedipine or indomethacin as a substitute, the older physicians dug in deeper in their intransigent support of magnesium as a tocolytic. But the literature was not only stating that magnesium didn’t help, it was suggesting that it was, in fact, killing babies. This line of attack was particularly painful to its zealots.
The side effect and safety profile of magnesium had always been problematic. It was utilized in humans long before any safety studies were available. While its side effect profile was clearly superior to ethanol, it was still associated with side effects ranging from nausea and vomiting to pulmonary edema, urinary retention, respiratory depression and maternal death.
But neonatal risks were largely undetermined. Recall that one of the first prospective trials of magnesium as a tocolytic, performed by Cox et al. at Parkland (1990), found 8 fetal or pediatric deaths in the magnesium group compared to only 2 in the placebo group. This was an alarming finding, particularly since magnesium was also found to be ineffective at arresting labor.
Still, many of the folks who have been ardent supporters of magnesium tend to discount randomized, placebo controlled trials. But magnesium supporters were thrilled with a 1995 study by Nelson and Grether. The authors did a retrospective, case-control study in California of 155,636 children followed to age 3. They found that 7% of very low birth weight (VLBW) babies who developed cerebral palsy (CP) had been exposed to magnesium in utero while 36% of VLBW babies who did not develop CP had been exposed to magnesium. In other words, VLBW babies who did not develop CP were more likely to have been exposed to magnesium in utero.
This surprising finding gave new energy to the magnesium enthusiasts and many were ready to declare that magnesium would prevent cerebral palsy in preterm infants, even before quality evidence was available. The numbers in the Nelson and Grether study sound impressive: 155,636 children enrolled, with 7% magnesium exposure in the CP arm compared to 36% exposure in the non-CP arm. But allow me to write a different summary that reflects the actual findings of the study:
We reviewed the charts of 155,636 births occurring between 1983-1985. We found 117 infants who were born weighing less than 1500 grams. 42 of these children went on to develop cerebral palsy while 75 did not. 39 of 42 children who later developed CP were not exposed to magnesium nor were 48 of 75 children who did not develop CP. We were unable to control for differences in quality of care at different nurseries or other institutional factors. It is possible (if not likely) that institutions using magnesium sulfate tocolysis in 1983 were tertiary care centers associated with higher quality neonatal care units.
So I have two points to make. First, perspective and bias matters when interpreting observational data. There are thousands of potential explanations of this data. Second, be careful not to be wowed by irrelevant data. Dozens of publications reported on this study by stating, “A retrospective study of over 150,000 children…” This is a way of intentionally biasing the reader. What if instead the first sentence were, “A small, retrospective study of 117 children with poorly controlled variables found …”? Nevertheless, this small retrospective study of 177 poorly matched children led to the MagNET trial.
In MagNET (Magnesium and Neurologic Endpoints Trial), women in preterm labor dilated less than 4 cm were randomized to magnesium versus another tocolytic, while women dilated more than 4 cm were randomized to magnesium versus saline. The trial was stopped at 15 months because of the high rate of pediatric mortality noted in the magnesium group (10 deaths in the magnesium group vs 1 in the placebo group; p=0.02).
The authors (Mittendorf et al.) later published other findings collected from the MagNET data. They found that:
This type of dose-dependent relationship is very important as evidence of causation, rather than just correlation. The IVH data also supports the proposed biologic theory that magnesium may have an anti-platelet aggregation effect and therefore an anticoagulant affect. Indeed, 25% of infants who died had Grade III IVH compared to only 2% of survivors, with ionized magnesium levels of 1.00 mmol/L among infants with Grade III IVH compared to 0.67 mmol/L in infants with Grade I IVH. These data, too, were statistically significant. IVH in turn is associated with apneic events, a common causes of death among these infants. Let’s note that children who survive with Grade III or IV IVH are also far more likely to develop CP (meaning that one would expect a lower rate of survivors with CP if newborns with advanced CP were eliminated from surviving).
In order to address the question of whether a lower dose of magnesium exposure might have some protective effect against CP, the authors evaluated 67 surviving children and compared their neurodevelopmental scores to their serum ionized magnesium levels and found no statistically significant relationship.
Scudiero et al. in 2000 followed up MagNET with a case-control study at the Chicago Lying-In Hospital in which they found that exposure to more than 48 grams of magnesium was associated with a 4.72 odds ratio of fetal death. These findings were consistent with MagNET which indicated that the higher the dose of magnesium, the more likely the adverse event. Note that the typical tocolytic magnesium dose exposure is on average over 50 grams for a 48 hours course. This finding led advocates of magnesium to investigate low-dose magnesium protocols.
Crowther et al. in 2003 published results from the ACTOMgSO4 (Australasian Collaborative Trial of Magnesium Sulphate) study. They randomized low-dose magnesium versus placebo in 500 women and found no significant difference in the rate of cerebral palsy, which was the primary outcome studied.
There was an apparent “trend” towards fewer cases of CP and less developmental problems. “Trends” are code for “We didn’t find anything but surely it’s not all a waste of time.” Taking into account these trends, and presuming (which is quite a stretch) that the trends would continue over a larger population, Mittendorf et al. concluded that approximately 392 cases of CP could be prevented each year at the cost of 1900 infant deaths. Both of these numbers are, of course, incredibly speculative and add little to the discussion, but they are the results of using the then available data.
In December of 2006, Marret et al. published results of the PreMAG trial, in which 573 preterm infants at risk of delivery in the next 24 hours in 18 French hospitals were enrolled between 1997 and 2003 to receive either 4 gr of magnesium or saline. They found no statistically significant differences in outcomes among the two groups.
All of the studies available up until this point were reviewed by the Cochrane Database and they concluded:
…antenatal magnesium sulfate therapy as a neuroprotective agent for the preterm fetus is not yet established.
Finally, Rouse et al. in 2008 published results of the BEAM Trial (Beneficial Effects of Antenatal Magnesium), started in 1997 by John Hauth, after the highly flawed Nelson and Grether study was published. The idea was conceived in 1996. Hauth is a very influential advocate for magnesium; he and others wrote a critical response to the David Grimes editorial that boldly condemned magnesium sulfate tocolysis in 2007. Their letter begrudgingly concludes,
We agree that magnesium sulfate may not keep fetuses in utero, but the totality of the available data does not support that it in any way harms them.
I point this out only for consideration of bias on the part of the investigators and authors of the BEAM study. These authors were setting out to prove that magnesium was not the bad agent that people were claiming that it was, that they had not been harming women, and that it served some purpose, even if it ‘may’ not keep fetuses in utero. That sentence alone (and the name of the BEAM study) shows the bias. By the time Grimes wrote that editorial in 2006, we knew unequivocally that magnesium ‘did’ not keep fetuses in utero – no ‘may’ about it; but that admission is sometimes too much for those so cognitively dissonant.
Hauth and colleagues performed a retrospective pilot study on the effect of magnesium on neonatal neurologic outcomes which was published in 1998. The analysis of 799 VLBW infants found no difference in those exposed to magnesium compared to those who were not exposed. Still, the BEAM Trial went forward.
The BEAM Trial randomized 2241 women at risk for preterm delivery (mostly with preterm rupture of membranes) to magnesium versus placebo. The primary outcome to be studied was the incidence of moderate or severe cerebral palsy or death, and no significant difference was found between the two groups. Their conclusion,
Fetal exposure to magnesium sulfate before anticipated early preterm delivery did not reduce the combined risk of moderate or severe cerebral palsy or death…
And here the debate should have ended. The primary outcome was designed to be an aggregate inclusive of death and moderate or severe cerebral palsy because the data available at the time the trial was designed had at least suggested that a mechanism by which the number of survivors having moderate or severe CP might be reduced was through culling out the most vulnerable babies (the Grade III and Grade IV IVH neonates) by giving them a drug with anticoagulant properties that increased the risk of death. When I say ‘culling out,’ I am trying to find a respectful word for ‘killing’ since these are real human babies I’m discussing. Remember, the MagNET trial was ended prematurely because this hypothesis was supported by its unexpected findings. MagNET, ACTOMgSO4, PreMAG, a Cochrane meta-analysis, Hauth’s pilot study, and now BEAM had all failed to show a statistically significant decreased risk of cerebral palsy without, at the same time, causing excessive death.
But hope springs eternal for the true believer.
After failing to demonstrate a significant difference in the primary outcome of death or CP, two secondary analyses were performed: death alone and moderate or severe cerebral palsy alone. In other words, the primary aggregate outcome, for which the study was powered and designed to detect, was split into two separate outcomes.
For death alone, there was an excess of 10 fetal deaths in the magnesium group but this did not rise to the level of statistical significance. For moderate or severe cerebral palsy alone, there was an excess of 18 cases of CP in the placebo group and this was statistically significant (reported P value of 0.03). From this secondary analysis, subsequent meta-analyses were performed, and through the magic of faulty frequentist methodologies of statistic analysis, the trials previously discussed along with BEAM were repurposed to show that magnesium in fact was associated with a decreased risk of CP without an increased risk of death. Common sense alone tells us that the primary aggregate outcome of the BEAM Trial should have been statistically significant if this were the case, but in the shady world of meta-analysis, anything can and often does happen (particularly when the authors are agenda-driven).
So a few points about BEAM’s conclusion that “the rate of cerebral palsy was reduced among survivors.” Below is the statistical data provided by the authors for the primary outcome (CP or death) and the two subset analyses (CP alone or death alone) for both ‘all pregnancies’ and ‘pregnancies without major congenital anomalies.’ Notice that the entire deck of cards is predicated on just two P values, shown in red:

First, a few points about these P values.
But why stop here? The authors also cleverly buried one additional point. There were four sets of twins in the study where one twin died and one twin survived with cerebral palsy. If you or I were designing this study, we would likely decide to exclude these four pregnancies, because in utero death of one twin is a significant risk factor for CP in the surviving twin, as much as a 25% risk. But what’s worse, the pregnancies were unevenly distributed: only one set was in the magnesium group while three were in the placebo group. Twins in general were unevenly distributed between the two groups: 92 in the magnesium group with 111 in the placebo group.
But the authors chose to make the denominator for all relevant calculations the total number of pregnancies, not the total number of fetuses. So the placebo group has a disproportionate number of fetuses compared to the divisor, which the authors didn’t fix because it only really mattered in these four pregnancies (though in fairness, the numerator of healthy babies would have been 19 bigger in the placebo group if they had adjusted it – they did not because this would dilute the beneficial effects they were hoping to find in the magnesium group). Confused? Don’t be; I have done what the authors should have done: excluded just the four mismatched twin pregnancies. Here is the data with those four pregnancies excluded:

That’s right. Not a single significant P value, even if the nominal (and incorrect) value of 0.05 is used.
Now the Bayesian reader of the BEAM Trial is not surprised by any of this, even if she did not take the time to redo the Fisher Exact Tests (and what good Bayesian would?). Why? The claim that there was a reduction of moderate or severe CP doesn’t make sense in the context of reported outcomes. Specifically, the authors report Bayley Scales of Infant Development, with subset that include Psychomotor Development (at two different thresholds) and Mental Development (again with two different thresholds). None of these four measures were different between the magnesium and placebo group. In fact, the best P value was 0.83. In other words, even if the reduction in the risk of CP were significant (it isn’t), then a better explanation of the data would have been that the subjective diagnosis of CP was greater in the magnesium group, but objective neonatal outcome did not support this difference.
If all this weren’t enough, here is another fatal flaw: data from a subset analysis should not be used to change clinical practice (in most cases). Rather, it is preliminary data that should be used to inform a sufficiently powered clinical trial to address the suspected finding. Why? Simply because the subset is not appropriately powered to find the differences of importance. For example, let’s say that the finding of a reduction in CP were significant (it wasn’t, but pretend), then it might be possible to say that this finding is statistically valuable, but the same subset analysis may not have been appropriately powered to detect a commensurate rise in the risk of death. In fact, using the authors’ nominal data, that is exactly what has happened. The increase in death in the “All pregnancies” group showed a rate of mortality of 8.5% in the placebo group versus 9.5% in the magnesium group. This full 1 percentage point increase represents 10 babies per 1000, and it is easy to do the math to see how many patients would need to be enrolled to test the statistical significance of this finding. Rarely are subset analyses sufficiently powered to answer such questions, particularly when the outcome is broken out of the larger aggregate outcome (death or CP) that the trial was initially powered to study.
Of course, death and CP are not equal in any way. How many survivors with CP is it worth avoiding to kill one baby? Is it 1:1, 5:1, 10:1, or some other number? I have shown explicitly the several reasons why there were no significant findings in the BEAM Trial, but if you are still holding out hope, then you need to consider this question. Ultimately, this is why the subset analysis is not meaningful. The change in CP rates and the change in death rates, the trends at least, are not equal, so a larger study is needed to observe if the change in death is real. Then a value judgment can be made about death versus living with CP. Physicians who are using magnesium for this purpose should be discussing this value with their patients.
At last, the BEAM Trial is just like the studies that had come before it: it suggests that CP may be reduced because the total number of survivors are reduced, but the findings do not rise to the level of statistical significance. The appropriate outcome to be studied was the combined outcome of death and CP, which again showed no significant difference even by the authors’ own attestation. Another way of looking at the data is to think about the total number of intact survivors in each arm of the study: 88.7% of the infants in the magnesium group were intact, whereas 88.3% of the survivors in the placebo group were intact. And if we take out the 4 sets of twins with death/CP that were distributed unevenly, then those numbers change to 88.75% and 88.56% respectively. Neither set of these numbers is anywhere near statistically significant and obviously not clinically significant.
Some other problems:
The follow-up meta-analyses that have been published, including the favorable Cochrane review, are distorted due to the statistical games played in the subset analysis of the BEAM Trial. If the subset analysis is restored to is true significance, then the meta-analyses fall apart. As a larger lesson, this shows how important intellectual honesty is in the way data is presented. The BEAM Trial has been cited in over 300 papers since it was published, and it has all but replaced the significance of the previous studies with which it attempts to disagree. This shows the confirmation bias of the many authors who have latched onto the study who ignore the other data because this paper tells them what they want to hear: Magnesium is good.
Usage of magnesium for premature labor, after a gentle decline in the early 2000s, has now exploded again and a generation of physicians who could not stand against the march of evidence that destroyed magnesium as an effective tocolytic now feel justified again. Meanwhile, women and children suffer (for example, this large 2015 study found that infants exposed to magnesium had a 1.9 fold higher NICU admission rate after adjusting for other variables).
When we are not disciplined in utilizing evidence based medicine to inform our decisions, it sometimes takes generations to overcome the mistakes made. Literally hundreds of years were spent bleeding women for eclampsia. Fifty years has been wasted on a magnesium as a tocolytic, and many are still using it for this indication today. And now the bait-and-switch of prevention of cerebral palsy. It doesn’t have to be another fifty years before we realize that this too was a false path; we just need to apply rigorous techniques to the data we have, consider the pre- and post-study probabilities of this hypothesis, and adjust those probabilities as new data emerges.
Prior to the BEAM Trial, the pre-study probability that magnesium had a beneficial effect on neurological outcomes of exposed neonates was very low. BEAM did not change this. New data will emerge. For example, in 2014, long term pediatric data was published regarding the children who had been enrolled in the ACTOMgSO4 trial. I’ll bet you can already guess the conclusion:
Magnesium sulfate given to pregnant women at imminent risk of birth before 30 weeks’ gestation was not associated with neurological, cognitive, behavioral, growth, or functional outcomes in their children at school age…
The authors of the PreMAG trial also performed school age follow-up on children enrolled in their study and found no difference in outcomes. Interestingly, these are the two trials which Rouse cited as support for the BEAM Trial and their statistics have been perverted by subsequent meta-analyses.
Magnesium is great for the treatment of preeclampsia/eclampsia. Let’s stop pretending it’s a panacea.
Published Date : August 10, 2016
Categories : Evidence Based Medicine, OB/Gyn
It was a happy accident that magnesium was discovered to reduce the risk of seizures in women with preeclampsia with severe features; and it was wonderful because it replaced so many barbaric interventions, like suboccipital trephining. After the discovery of insulin and other important medical breakthroughs in the 1920s and 1930s, physicians became inspired to apply the scientific method to medical problems. Many were eager to abandon some of the seemingly barbaric practices that had defined medicine of the last century.
By the 1950s, Obstetrics had been on a great run for the previous 100 years. Maternal mortality had dropped from about 1% per pregnancy (8-9% lifetime risk) to under 0.05% per pregnancy, a 20-fold decrease. Neonatal care was improving. Surgery was becoming dramatically safer. Many problems which had been a low priority in the minds of obstetricians now had the luxury of being tackled. One of these was preterm labor.
The first editions of Williams’ Obstetrics treat premature labor as a subset of miscarriage with just a few pages of discussion. Though syphilis was largely blamed, there was no antibiotic treatment. Williams opined that narcotics and bedrest might have some impact, but only in the very earliest stages of preterm labor. No real hope or treatments were offered.
Joseph DeLee’s 1943 edition of Principles and Practice of Obstetrics offers less than one page about premature labor, and reports that E. Shute was using high doses of Vitamin E for treatment (an interesting read), while others were advocating the use of “corpus luteum extract.” Vitamin E (and C) are still the subject of some investigation for prevention of preterm labor, but neither has shown benefit. Corpus luteum extract, better known as progesterone, has, of course, become a mainstay of the prevention of recurrent preterm labor, but has not been shown to have an effect once labor starts.
The 1965 edition of DeLee’s text (Greenhill’s Obstetrics), which includes the latest information about electronic fetal heart monitoring, doesn’t dedicate any space at all to premature labor. By 1965, we had sent a spacecraft to the moon (the Soviets at least), but we had no treatment to offer women with premature labor. This was soon about to change, however.
In 1967, Fuchs et al. reported that IV ethanol was an effective treatment for premature labor. Zlatnick and Fuchs reported in 1972 that among women dilated less than 3 cm, ethanol cut the rate of premature delivery within 72 hours in half. The poorly controlled study of 42 women was typical of medical literature of the time; the ability of ethanol to stop or delay delivery has since been thoroughly repudiated. Nevertheless, for obstetricians desperate for some intervention, it was a godsend. Ethanol became widely popular in the decade following Fuchs’ 1967 paper. But the side effects of intoxicating pregnant women for days at a time were horrendous. Doctors were searching for something – anything – that might be better.
Note what happened: a de facto standard of care was created for ethanol. Prior to 1967, no interventions were routinely utilized for premature labor; but by the mid-1970s, it was standard of care to intervene. Obstetricians at the time were unaware that their intervention was no better than placebo. They didn’t feel that they could just stop using it due to its horrible side-effects, though they desperately wanted to. So the atmosphere was ripe for a replacement.
Beta-adrenergic drugs such as ritodrine, salbumatol, and orciprenaline were being investigated in the mid-1970s, as well as aspirin and indomethacin, for the treatment of preterm labor, but investigators were hesitant because the results were mixed. For example, Castrén et al. in 1975 conducted a double blind study where patients were given either placebo, nyldrin (a beta-mimetic), isoxuprine, or alcohol. They found no difference between placebo and alcohol or the other drugs in terms of on-going pregnancy at 7 days. In fact, 73% of women were still pregnant at one week with placebo versus 56% of women with ethanol.
Studies of the time regarding tocolytics suffered from several methodological flaws.
Indeed, a lack of awareness about the natural course of preterm labor or at least the placebo-affected course of preterm labor on the part of physicians led to an overestimation of the importance of tocolytics in the 1970s. If more than 70% women who presented in preterm labor were reported to stay pregnant for some interval of time, say one week, then the drug was felt to be effective. But a placebo-controlled arm would have shown a similar rate for no intervention.
Enter The Magnesium
As obstetricians were gaining experience with magnesium for the treatment of preeclampsia and eclampsia, an anecdotal body of knowledge developed. By the 1950s and 1960s, most obstetricians had managed the labors of preeclamptic women who were on magnesium for seizure prophylaxis. In 1959, Hall et al. published a paper that claimed that uterine contractions were slowed in preeclamptic women on magnesium. Hutchison in 1964 made similar observations. In vitro studies conducted in Germany and Japan in the 1960s had shown that myometrial tissue bathed in magnesium had slowed muscle contractility. Hutchison actually stated that “magnesium sulfate is capable of reducing uterine tone with subsequent enhancement of uterine contractions.”
Lamont in France started using magnesium for tocolysis in 1965. It was also used as a tocolytic starting in 1969 at Columbia-Presbyterian in New York and by Petrie at the University of Virginia in 1970. Petrie in 1976 reported that magnesium appeared to slow uterine activity but also said,
These data refer only to uterine activity. No attempt is made to correlate these results to an effect on the course of labor. … Uterine activity is an integral aspect influencing labor but it probably cannot be correlated directly to the progress of labor.
Petrie, who made this comment after 6 years of informal experimentation, was ahead of his time. One of the great cognitive distortions that has plagued obstetricians is the idea that contractions are correlated to labor. Sounds bizarre? The vast majority of contractions that a woman experiences in pregnancy do not lead to cervical change, even very powerful contractions in some cases (as opposed to Braxton Hicks type contractions). Only a very few contractions (less than a 100 in many cases) can lead to complete dilation and delivery of a woman at term who is ready to deliver (while the 1500 she had the prior ten weeks did nothing more than lead to perhaps 2 cm of dilation). Labor requires two things: the background cervical ripening and remodeling first, then sufficient uterine contractions to push the baby out of a ready cervix.
We can observe when contractions happen but we don’t really yet understand when the cervix is prepared for labor; consequently, the majority of women thought to be in preterm labor are not and therefore even placebo is sufficient to prevent over 70% of women from “laboring.” At the same time, non-labor contractions are effectively calmed with rest, hydration, a tincture of time, and any tocolytic one might care to use. But this suppression of uterine activity has not been shown to change the timing of eventual delivery, and this was Petrie’s point.
I might also add that in the management of term labors, we have seen over-utilization of cesarean delivery because providers cannot understand how so many hours of strong uterine contractions has not effected cervical change; but the cervix in those cases (usually inductions or augmentations) was not ready, so the time is less relevant. This exaggerated sense of the importance of uterine contractions in labor has lead to substantial harm to pregnant women over the decades and still wrongfully dominates our thought processes.
Because of this thinking, though, physicians of the era were very excited to see anything that would lead to diminishment of uterine activity, even ethanol, let alone something with a better side effect profile, like magnesium or indomethacin. By the end of the 1970s, the first clinical trials relating to magnesium tocoylsis were published.
All three of these early trials lacked appropriate randomization and placebo-control. But due to both a visceral dislike of ethanol as a tocolytic and the promise that magnesium was at least as good as ethanol, magnesium sulfate tocolysis became the de facto standard of care before a single randomized controlled trial (RCT) was performed. Let’s look at those trials:
These are the only four placebo-controlled, randomized trials of magnesium as a tocolytic, and the conclusion is inescapable: it is worthless. There are other RCTs which compare magnesium to different tocolytic classes.
Magnesium has been compared to beta-mimetics in the following RCTs:
Thus, no differences (except fewer side effects) were found when comparing magnesium to beta-mimetics (and placebo in one case). Six RCTs have compared beta-mimetics to placebo. Three found no difference compared to placebo, while three poorly controlled studies showed slight prolongation of pregnancy. The largest and best designed of these studies, the “Canadian Ritodrine Study,” randomized 708 women to ritodrine or placebo and found no differences in perinatal mortality, birth weight, or prolongation of pregnancy.
Magnesium similarly has been compared in prospective trials to calcium channel blockers:
Here again magnesium and calcium channel blockers are no different with respect to neonatal outcomes or overall in respect to timing of delivery. Magnesium has also been compared to COX-inhibitors:
So too COX-inhibitors show no differences in outcomes compared to magnesium. Recall that ethanol was compared to magnesium by Steer and Petrie and no statistically significant difference in outcomes was observed either.
There are no placebo controlled trials for either calcium channel blockers or COX-inhibitors. Interestingly, these agents are held out today as the last remaining hope for tocolysis due to their favorable side-effect profiles compared to other (equally ineffective) agents, and because, in a small number of poorly designed studies, they compare favorably to beta-mimetics.
These are the available RCTs regarding magnesium. Put another way: magnesium, ethanol, beta-mimetics, calcium channel blockers, and COX-inhibitors are all equal in effect to placebo. Does this sound too bizarre to be true? Well don’t take my word for it. Let’s look at some systematic reviews:
In 2006, David Grimes wrote an editorial in the Green Journal about magnesium tocolysis, which at that time some 80% of obstetricians were continuing to use it as a tocolytic, despite having been repeatedly demonstrated as ineffective. All available data at that time also indicated that it was associated with a significant increase in total neonatal mortality, accounting for as much as 7% of total pediatric mortality. He concluded,
“Further use of this agent is inappropriate unless in the context of a formal clinical trial with institutional review board approval and informed consent for participants…Tocolysis with magnesium sulfate is ineffective, and the practice should stop.”
His editorial was widely attacked or ignored as magnesium’s use continued among maternal fetal medicine specialists. In fact, it created a backlash among magnesium’s most ardent supporters. Elliott, author of one of the original three studies on magnesium, wrote in a letter to the editor in 2009:
“Magnesium sulfate is effective in delaying delivery for at least 48 hours in patients with preterm labor when used in higher dosages. There do not seem to be any harmful effects of the drug on the fetus, and indeed there is a neuroprotective effect in reducing the incidence of cerebral palsy in premature newborns weighing less than 1,500 g.”
These comments were completely unsubstantiated and ignore every clinical study performed.
In 2009, Mercer and Merlino wrote the definitive analysis on magnesium sulfate for preterm labor in a Clinical Expert Series review in the Green Journal. They concluded that studies have,
“…failed to demonstate that magnesium sulfate is effective in preventing preterm birth or reducing newborn morbidities or mortality as compared with alternatives or no tocolytic treatment. Alternatively, beta-mimetics, calcium channel blockers, and cyclooxygenase inhibitors were not found to be superior when compared with magnesium sulfate treatment. Recent meta-analyses and randomized controlled trials do not provide consistent evidence of a reduction in newborn morbidities or mortality with these other tocolytic classes. … We did not find improvements in delivery at 48 hours, respiratory distress syndrome, or intraventricular hemorrhage with magnesium sulfate, and we did not find any other tocolytic class to be superiors to magnesium sulfate regarding these. It is disappointing that tocolytic treatment with magnesium sulfate and other agents has been so widely accepted in practice despite the relatively small number of patients studies and lack of evident benefits… Practitioners should reconsider their current practices regarding tocolysis with magnesium sulfate and other classes of tocolytic agents.”
Indeed. It is embarrassing that in over 5oo trials of tocolytics, none show fetal benefit and next to none show prolongation of labor. We would expect to find about 25 positive trials just based on a 5% rate of type 1 errors; but we do not. Mercer and Merlino conclude that it is appropriate to withhold magnesium sulfate as a tocolytic from women in preterm labor, and also appropriate to withhold treatment with beta-mimetics, calcium channel blockers, and COX-inhibitors.
If you have read so far, you are probably in disbelief. Alas, there is simply no scientific support of any tocolytic, especially magnesium. Nifedipine and indomethacin have filled the void for those who are trying to abandon magnesium, but not because those agents have been shown to help babies, but because they have a better side effect profile and it makes us feel good to do something for women in preterm labor. This should remind you of how magnesium replaced ethanol: we thought ethanol worked (it didn’t), ethanol had undesirable side effects, magnesium was as effective as ethanol (and placebo) in treating preterm labor, so we substituted. But it is time to start using the equally effective treatment which provides the lowest risk of harm to mother and baby: placebo. First do no harm is, after all, supposed to be our guiding ethic.
There are several lessons to be learned from all of this:
Magnesium was a wonder drug for women who had preeclampsia or eclampsia. But it was not a panacea. Nearly 50 years has been wasted on magnesium as a tocolytic, with countless women and neonates harmed; what’s more, research into more effective interventions has been stymied. Even in the last 5 years, scores of new “magnesium as tocolytic” publications are being published by the die-harders. And we still haven’t learned the lessons: tocolytics, including magnesium. are still overwhelmingly used in the treatment of preterm labor in the US and abroad.
It’s very hard to go back on deeply held dogmas. Entire careers have been spent by many physicians believing that magnesium was an effective treatment for preterm labor. Egos have been necessarily bruised by the data, however. So what’s a doc to do when he has spent an entire career giving this drug unnecessarily to patients? Find a new use or a new benefit; turn “evidence based medicine” back against those who discredited magnesium in the first place. The new savior of egos: prevention of cerebral palsy.
Published Date : August 8, 2016
Categories : Evidence Based Medicine, OB/Gyn

In this three part series, we will look at the evidence behind magnesium sulfate for treatment of three problems in obstetrics: prevention of maternal seizures in women with preeclampsia (Part 1), treatment of preterm birth (Part 2), and prevention of cerebral palsy in preterm infants (Part 3).
The history of magnesium usage in pregnancy is profoundly interesting. The drug has risen from a treatment of constipation to an obstetric panacea in the minds of many; but while one indication proved accidentally valuable (prevention of seizures), another was nothing more but wishful hope for a savior (treatment of preterm labor), and the last indication is a case-study in the misuse of statistics by those who cling to dogma and pet-theories (prevention of cerebral palsy).
Eclampsia
Eclampsia is the presence of grand-mal type seizures (or possible post-ictal coma) in pregnancy without other explanations, occurring before, during, or after labor and delivery. It is usually associated with preeclampsia. Today, in the United States, maternal and perinatal mortality due to eclampsia is rare; however, it remains a significant cause of mortality in the third world. Magnesium sulfate IV or IM is used to prevent seizures in women with preeclampsia with severe features, as well as prevent recurrent seizures in women with eclampsia. (Current terminology and criteria for preeclampsia are available here.)

History of the treatment of eclampsia.
In 1916, Joseph DeLee reported that mortality from eclampsia ranged from 20-45%. Williams, in 1908, reported that maternal mortality ranged from 20-25% and fetal mortality from 33-50% (Williams Obstetrics, 2nd edition). Management of preeclampsia/eclampsia in that era consisted mainly of sedation (with morphine and/or chloroform) and delivery. Since there was no good method of induction, mechanical and surgical methods of induction were often employed and cesarean delivery was used by the more aggressive physicians or in the more severe cases.
By 1930, Williams (6th edition) lists both radical treatments for eclampsia/preeclampsia (involving methods of effecting rapid delivery) and the following “conservative” treatments:
Why magnesium?
In a world of trephining and renal decapsulation, Lazard’s magnesium sulfate seemed rather innocuous. Indeed, no controlled studies existed for any of these interventions, so treatment choices of the time typically gained favor if they seemed to provide an acceptable result without much harm. The idea of magnesium salts started as a form of catharsis to purify women of toxins. Proteinuria was felt to indicate the need for dietary protein restrictions, and anything that caused diarrhea was viewed as a positive. Oral ingestion of Epsom salts typically would cause diarrhea. Obstetricians were familiar with this since it was used commonly to treat constipation of pregnancy. When a woman developed toxemia, it made sense to them to use it as a cathartic in combination with gastric lavages and enemas.
The first “infusions” of magnesium were thus done rectally. Rissman also injected magnesium sulfate intrathecally as early as 1906 (after performing a lumbar puncture), believing that it acted as an antitetanic agent since he believed that the toxins of eclampsia worked similarly to the tetanus toxoid. Magnesium sulfate had already been used as treatment of tetanus, though modern literature has shown it to be ineffective. So magnesium entered into the picture as both an “antitetanic” and a “cathartic.” Since it was relatively benign compared to other treatments, its use became more common. Rissman reported that rectal infusions resulted in fewer convulsions, and indeed they may have given what we understand today. This observation was the basis for Lazard’s simplified treatment. By 1933, he had reported on over 500 women who had received magnesium intravenously at Los Angeles General Hospital, using a small dose. Ultimately, Jack Pritchard and Frederick Zuspan built upon Stander’s, Eastman’s, and Steptoe’s work to give us the current dose regimen we utilize today.
Jack Pritchard, working at Parkland Hospital in Dallas, is largely responsible for making magnesium sulfate the standard of care for prevention and treatment of eclamptic convulsion. In 1955, Pritchard reported on 211 patients with either preeclampsia or eclampsia who received a 4 gram IV bolus of magnesium sulfate followed by repeated dosing, with only one maternal death. By 1975, he reported on an additional 154 eclamptic women who were treated with magnesium sulfate, antihypertensives, induction of labor, and supportive care, and there were no maternal deaths and no deaths of newborns who weighed over 4 lbs.
In the modern era of obstetrics, we have several advantages in treating preeclampsia/eclampsia, including effective antihypertensive agents, ICU support, effective methods of induction of labor, safe cesarean delivery, etc. Today, at least in the United States, death or significant morbidity from eclampsia is exceedingly rare.
John Moran recalled Horace in 1921 when discussing the then treacherous management of eclampsia:
The keynote in the treatment of eclampsia is prevention. Yet either in the prevention or treatment of actual eclampsia an even mind is essential. “Aequam memento rebus in arduis servare mentem,” as the old Latin bard has sung.
Indeed prevention remains our most valuable tool. Our system of prenatal care, with more frequent visits towards the end of pregnancy, is predicated upon detecting preeclampsia before severe symptoms arise, and then ending the pregnancies as soon as reasonable to prevent eclampsia from occurring.
How do we prevent preeclampsia?
Primary prevention of preeclampsia/eclampsia has been studied extensively. Currently, only ASA 81 mg daily is recommended for primary prevention of preeclampsia among women at high risk for development of preeclampsia. Other interventions, such as Vitamins C, E, fish oil, calcium, zinc, and salt restriction, have not proven beneficial.
Secondary prevention of eclampsia involves delivering those who are risk of progression from gestational or chronic hypertension to preeclampsia or those with preeclampsia with severe features to eclampsia. This is accomplished by early detection and timely delivery, along with the use of antihypertensives and magnesium sulfate in some cases. In the past, there has been controversy about which patients benefit from magnesium for the purposes of seizure prophylaxis, with some offering it to all hypertensive patients while others have restricted it to those with severe features. The current management of hypertension in pregnancy is guided by the ACOG Task Force on Hypertension in Pregnancy. They recommend that,
For women with preeclampsia with systolic BP of less than 160 mm Hg and a diastolic BP of less than 110 mm HG and no maternal symptoms, it is suggested that magnesium sulfate not be administered universally for the prevention of eclampsia.
This should, for now, settle the debate about whether magnesium should be used prophylactically in preeclamptic patients without severe features, but, nevertheless, the practice remains common. Other preventative measures not recommended by the Task Force include bed rest. The Task Force also recommends delivery of preeclamptics at 37 weeks of gestation or at no later than 34 weeks of gestation if severe features are present, as part of secondary prevention.
Tertiary prevention of eclampsia involves preventing recurrent seizures among women who have already delivered, and, here again, the interventions are magnesium, antihypertensives, and delivery.
What’s the evidence for using magnesium?
For treatment of women with severe disease (preeclampsia with severe features):
For treatment of women with mild disease (preeclampsia without severe features):

How does magnesium prevent seizures?
Magnesium has been shown to be superior to a variety of anti-epileptic drugs for the treatment of eclamptic convulsions, such as phenytoin and diazepam. For this reason, it is thought to have a mechanism of action independent to that of the most anti-epilpetic drugs, but we do not know the actual mechanism of action. A variety of theories have been proposed, but none as of yet has substantial evidence. Most involve effects on the blood-brain barrier and its ability to antagonize depolarizations or block the NMDA-receptor ion channel. It is important that we do not make over simplifications for how magnesium works; I once heard that it reduced seizures because it retarded the activity of muscles (this explanation undoubtedly made sense to the person who said it, since it also stopped uterine contractions in his mind). Wild guesses and speculation do not often advance science. What we know is what the data shows: Magnesium prevents seizures by about 50% among women with preeclampsia with severe features, and possibly maternal mortality. That’s all.
In the end, magnesium did work to prevent seizures, but for all the wrong reasons. Yet, its proponents, who were wrong in their belief that it would work as a cathartic or a antitetanic, felt redeemed by the fact that it prevented seizures, helping them save face after a career of claims that were not, at first, based in evidence. We will see this pattern repeat itself. Magnesium was used for generations as a tocolytic, despite no evidence of benefit or efficacy. Yet, its adherents have been steadfast, hoping for justification in the end. This time, it came in the form of an “evidence based” benefit of preventing cerebral palsy. Surely, if this benefit were genuine, then two generations of nonscientific use of magnesium would be redeemed at last.
Physicians are horrible for falling prey to the “Law of the Instrument,” populary stated as, “If the only tool you have is a hammer, everything looks like a nail.” This form of confirmation bias helps us understand why magnesium sulfate, the high-risk obstetrician’s little tool, was wielded next on the problem of preterm labor.
Published Date : August 7, 2016
Categories : Quotes
Simplicity is the ultimate sophistication.
– Leonardo DaVinci
Published Date : August 2, 2016
Categories : OB/Gyn
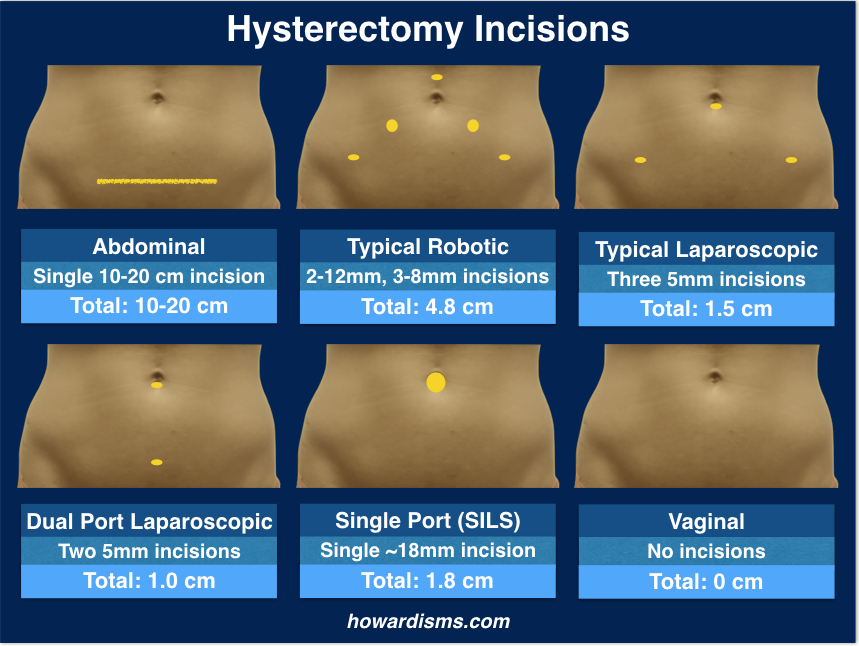
Total vaginal hysterectomy (TVH) is the preferred route of hysterectomy. Consider the following facts:
Despite these clear and undisputed facts, vaginal hysterectomy appears to be on the decline. Dr. Thomas Julian has written a wonderful and prescient commentary (in 2008) about this paradox, entitled Vaginal Hysterectomy: An Apparent Exception to Evidence-Based Decision Making. He discusses some of the reasons for its decline, include clever marketing, the myth that “newer” equals “better,” and, mostly, a lack of training for current residents and post-graduates, who more and more feel uncomfortable performing what I (and I suspect Dr. Julian) consider to be the easiest method of hysterectomy. Consider these facts:
So when will the decline in vaginal hysterectomy end? What can be done to reverse the trend? Why don’t doctors believe in evidence-based medicine? All of these are excellent questions. I suspect that the trend will not reverse itself until payers start insisting that less expensive hysterectomies be done whenever possible. I believe that teaching residents (and post-graduates) a simplified approach to vaginal hysterectomy, so that they are more comfortable with the procedure, can aid in increased utilization. And, yes, doctors do not believe in evidence-based medicine; even many of those who claim to actually do not. C’est la vie.
Here is my simplified approach to TVH:
Here are two videos showing the technique. This first video (7 minutes) highlights the major parts of the technique with an emphasis on how to use the Ligasure safely. The concern for thermal injury has prevented many physicians from incorporating energy sealing devices into vaginal surgery, but patient outcomes have been consistently demonstrated to be equal or better when an energy sealing device is used. This video demonstrates the parts of the technique which maximize thermal safety:
The second video is the full length video (23 minutes) of the same surgery with step by step explanations and details of each step:
Ultimately, there is no right or wrong way to do a vaginal hysterectomy. However, if you cannot do the following, then you should consider converting to a different route:
The rest is creativity.
There are some things which have been traditionally taught that serve to make the case unnecessarily difficult. For example,
There are few real contraindications to a vaginal approach. Still, there are some things that make a vaginal hysterectomy more difficult. Victor Bonney said in 1918,
The more one performs vaginal hysterectomy, the less contraindications one encounters.
Any skilled vaginal surgeon will whole-heartedly agree with Bonney. X. Martin et al. reported in 1999:
There is no absolute contraindication to vaginal hysterectomy. (Il n’y a aucune contre-indication formelle a l’hystérectomie vaginale.)
Still, there are impediments, whether real or psychological. Here are some:
Here are some tip and tricks for each of these impediments:
Nulliparity and Lack of Descent
Agostini et al. in 2003 prospectively compared vaginal hysterectomy outcomes in 52 nulliparous and 293 primiparous or multiparous women. The mean operative time was significantly longer in nulliparous patients (95 vs. 80 minutes), but vaginal hysterectomy was successfully performed in 50/52 of the nulliparous and 292/293 of the parous patients, suggesting that nulliparous women can be considered candidates for vaginal hysterectomy.
Varma et al. in 2001 did a prospective study of patients without prolapse who underwent hysterectomy for benign conditions. There were 97 abdominal and 175 vaginal procedures, with no significant differences in patient characteristics. The frequency of complications was low and similar in both groups.
Tips for nulliparity or lack of descent.
Prior Cesarean Deliveries/Difficult Anterior Colpotomy
Sheth et al. in 1995 performed a retrospective review comparing the vaginal hysterectomy outcomes of 220 women with prior cesarean deliveries (one or more) to 200 patients with no previous pelvic surgery. Only 3 of the 220 patients had inadvertent urological trauma intraoperatively. Factors favoring a successful vaginal approach were: only one previous cesarean, a freely mobile uterus, previous vaginal delivery, uterus not exceeding 10-12 weeks size, and absence of adnexal pathology. Infection following the previous cesarean was an unfavorable prognostic factor due to an increased risk of dense adhesions between the bladder and cervix. The authors concluded, “The vaginal route is the route of choice for performing a hysterectomy in patients with previous cesarean section.” I usually feel much more confident dissecting scarred bladders off of uteruses vaginally than abdominally.
Tips for the difficult anterior colpotomy.
Large Uterus
Sizzi et al. in 2004 performed a prospective study that evaluated vaginal hysterectomy outcomes in 204 consecutive women with a myomatous uterus weighing between 280 to 2000 g. Vaginal morcellation was performed in all cases. No patient had uterovaginal prolapse. Four patients underwent conversion to a laparoscopic procedure for the completion of the hysterectomy (two of these ultimately required laparotomy). Adnexectomy was successfully performed vaginally in 91% of patients in whom it was indicated. The authors concluded that traditional uterine weight criteria for exclusion of the vaginal approach may not be valid.
Expert vaginal surgeons are quite comfortable in removing larger uteruses vaginally. There is an informal “kilo club” of vaginal hysterectomists who have removed uteruses weighing more than a kilogram (no longer an uncommon feat) and I have even heard of a “two kilo club,” but have yet to join it. The key is morcellation. Taylor et al. in 2003 showed that vaginal hysterectomy with morcellation provided better outcomes for uteruses up to 1 kilo than did abdominal hysterectomy. There are several methods for morcellation:
Tips for morecellation.
The Obliterated Posterior Cul-de-sac/Endometriosis/Difficult Posterior Colpotomomy
A truly obliterated posterior cul-de-sac is rare and is most often associated with stage 4 endometriosis or prior pelvic infections. Difficult posterior colpotomies in the absence of adhesions are rare and usually the result of dissection in the wrong plane (usually too close to the cervix). Most patients who undergo hysterectomy for chronic pelvic pain or advanced endometriosis have had prior diagnostic laparoscopies so that an obliterated cul-de-sac is hopefully not a surprise. Another strategy for preoperative detection of an obliterated cul-de-sac is a vaginal ultrasound, applying the visceral slide adhesion imaging technique to the cul-de-sac. I have found this almost universally feasible. A thorough preoperative exam is very helpful as well, either in the office or under anesthesia.
If the posterior cul-de-sac is obliterated, then consider:
If the cul-de-sac is not obliterated, but posterior colpotomy is difficult, then consider:
Need for Adnexectomy
Multiple studies show a > 95% success rate in vaginally removing ovaries (or fallopian tubes alone). Davies et al. in 2003 were successful in 97.5% of cases. Need for concomitant oophorectomy should be rare, if evidence-based decisions are made. Prophylactic salpingectomy is controversial at best, but virtually all tubes can be removed vaginally if desired (it is easier to remove a tube than an ovary).
Obesity
Isik-Akbay et al. in a 2004 study concluded that vaginal hysterectomy was the superior and preferred approach for obese women, with a lower incidence of postoperative fever, ileus, urinary tract infection and shorter operative time and hospital stay. Exposure of the operative field can be difficult in obese women, regardless if an abdominal or vaginal route is taken. I, for one, would much rather “struggle” at a vaginal hysterectomy of a morbidly obese woman than struggle with exposure at an abdominal hysterectomy in the same patient. Laparoscopic hysterectomy with obese women is often no easier, introducing new challenges like degree of safe Trendelenburg, length of instrumentation, safe ventilation, etc.
Tips for obese patients.
Prior Abdominal Surgery
Prior abdominal surgeries are an indication for the vaginal route. Avoid the risks of trocar placement in women with prior GI surgeries by using the vagina as an access route to the abdomen. We have already discussed mitigation of anterior bladder adhesions or the obliterated posterior cul-de-sac.
Other types of adhesions may be encountered. Women who have had prior cesareans may have adhesions of the anterior uterus to the anterior abdominal wall. This may be suspected intraoperatively by noting Sheth’s cervicofundal sign, which occurs when pulling on the cervix depresses the anterior abdominal wall. These type of adhesions are often the most difficult to manage but can usually be handled with sharp, intrafascial dissection. Laparoscopic-rescue might be necessary in severe cases.
Adhesions of small bowel or omentum are usually easily managed with direct dissection after artificial prolapse of the uterus (and more easily handled with a pair of Metzenbaums than with a laparoscope).
What Else?
The biggest contraindication to vaginal hysterectomy is a lack of experience, confidence, and enthusiasm by the operator. I have listed only a few brief tips and tricks. The truth is, most “difficulties” encountered are made phenomenally easier by using a thermal sealing device, like the Ligasure. This allows the surgeon to much more easily combat a lack of uterine descent and have confidence in the security and hemostasis of the uterine blood supply, greatly expanding the number of cases that are amenable to standard techniques. In the 1970, Robert Kovac showed that over 80% of uteruses could be removed vaginally by gynecologic residents, using the then available standard techniques. Simplified vaginal hysterectomy using Ligasure offers even more promise and easier, safer cases.
A Few More Points
There are few other things that we should do around the time of hysterectomy to ensure best outcomes.
Published Date : July 31, 2016
Categories : Cognitive Bias, Evidence Based Medicine

Sir William Osler editing his textbook of medicine in 1891 at Johns Hopkins.
Ah, Sir William Osler. Who doesn’t love a good Osler quote? My favorite:
One special advantage of the skeptical attitude of mind is that a man is never vexed to find that after all he has been wrong.
Few men in medical history are as venerated, referenced, quoted, and, dare I say, worshipped as Sir William Osler, “the Father of Modern Medicine.” Rarely have I heard a talk about medical ethics, professionalism, communications, or medical education, where the name of the Great One was not invoked in reverential awe.
We in medicine like our demigods. Medicine has Osler. Surgery has Halstead. Gynecology has Tait, Sims, Kelly, and Bonney. Obstetrics has Williams and DeLee. Don’t get me wrong: each of this men made important breakthroughs. But, in retrospect, they were wrong about almost everything they taught and believed. They were also each powerful personalities of their time, who weren’t necessarily better or smarter than the next guy (or gal), but just happened to be in the right place at the right time to be very influential. But they were definitely creatures of their time.
Joseph DeLee, for example, gave us routine episiotomy and forceps because he believed it would protect the brain from damage caused by the vagina and perineum. I wouldn’t call him the father of the obstetrics that I practice. Was there no other obstetricians of the time who disagreed with him on these (in retrospect) crazy ideas? There definitely were, but they did not have the pulpit to preach from that DeLee had.
Osler was given the greatest pulpit of his generation, as Physician-in-Chief of the well funded Johns Hopkins Hospital (where Halstead and Kelly also headed up their respective departments). Osler was 40 years old when he was so installed (Halstead was 37 and Kelly was 31 when they became Hopkins’ chairs). All of them were just regular guys, who had fairly pedestrian careers up until that point. Howard Kelly frankly had almost no career before being given the reins at Johns Hopkins, but he went on to profoundly influence generations of gynecologists, as Osler did internists and Halstead did surgeons. I suspect I was even named after him. One major impact Howard Kelly had on the field of gynecology was all but killing the then thriving field of vaginal hysterectomy in favor of abdominal hysterectomy (thanks for fighting the establishment, Noble Sproat Heaney).
We still have our demigods today. Physicians are overly-awed by the Distinguished Chair of Such and Such at Ivy League University. We put great faith in the intelligence and integrity of prolifically published professors who spend more time on the speaking circuit than taking care of patients. We aren’t too skeptical of their well-spoken talks of highly-cited papers. It seems a little too cynical to believe that these very successful folks might sometimes put self-interest or self-promotion in front of intellectual honesty and academic integrity. Of course, if you are fan of Retraction Watch like I am, you realize how compromised modern academic journals truly are. Academic medicine and science in general is chock full of folks looking to self-promote, in a quest to push forward their pet ideas, pepper the CVs on the way to tenure or promotion, and shows some success for their next round of funding. This New York Times piece is chilling.
Academic dishonesty and scientific misconduct are rampant today. Career pressure and the need for publications, combined with how easy it is make up data, modify data, or just use inappropriate statistical techniques, makes its very tempting to fudge things just a bit. Anil Potti made up data behind at least 10 hugely impactful cancer genomics papers from Duke University. Dipak Das of the University of Connecticut made headlines for his research into the health benefits of resveratrol, found in red wine. But over 140 of his articles have been retracted due to data falsification. Andrew Wakefield was famously banned from medical practice in the UK after he was convicted of scientific dishonesty in connection to his now retracted paper which claimed to establish a link between the MMR vaccine and autism.
The list of frauds goes on for days. How many people still believe that resveratrol is a legitimate thing, or that vaccines are linked to autism? These are examples of blatant data falsification, but dramatically more commonplace is data fudging or the use of inappropriate statistical methods. It seems the desire to be published is just too much for many “researchers.” Hundreds of papers are retracted each year. Even among the honest authors, peer-review does little to ensure that appropriate conclusions are being drawn or that appropriate methodologies are followed. Sometimes, we just know we are right if only we could prove it! Such is the milieu of academic dishonesty.
We are all only human, and even our demigods are biased and make honest mistakes. Fifty years from now, we will look back at today’s medical science in the same way that today we look back at DES and other medical mistakes of the last century. Forty years ago we were absolutely positive that IV alcohol stopped preterm labor, just as we today are “sure” of lots of things today that undoubtedly will not stand the test of time. This is the nature of scientific discovery. We are no smarter than Osler, Kelly, and Halstead. But at least these giants were men of integrity and honesty, who valued the scientific process and would never allow it to be corrupted by ego, fame-hunger, and manipulation of the peer review and the scientific publication process.
Which brings us to penis captivus.
What is penis captivus? A quick Google search reveals more than 81,000 hits on many leading health websites. The term is meant to describe when, during intercourse, the vagina so tightly clamps down on the penis that the penis cannot be withdrawn from the vagina. Apparently this is a medical emergency, as the penis becomes engorged and blood flow is cut off. The Internet loves penis captivus, with dozens of articles about the true but rare condition. Legitimate authors have researched the condition and written reviews in respected medical books and journals.
So what’s the problem? It’s likely all a fraud. One of the most influential case reports about penis captivus was written by Egerton Yorrick Davis in 1884 in the Philadelphia Medical News. Davis wrote his detailed case report in response to an article that had been previously published in the same journal by Theophilus Parvin entitled An Uncommon Form of Vaginismus.
Below is the E.Y. Davis letter:


This report was repeated dozens of times in the medical literature soon after its publication and eventually became standard fare in textbooks and literature reviews. No doubt it was a favorite of physicians everywhere for its bawdry content.
Egerton Yorick Davis, Jr. contributed many letters and case reports to medical societies over the years and several were apparently published, until his death by drowning shortly after writing the letter about penis captivus. The only problem is that Dr. Davis was a hoax. He never existed. Yorick was the court jester in Hamlet, whom Prince Hamlet speaks of in the famous monologue in the Fifth Act:
Alas, poor Yorick! I knew him, Horatio; a fellow of infinite jest, of most excellent fancy; he hath borne me on his back a thousand times; and now, how abhorred in my imagination it is! My gorge rises at it. Here hung those lips that I have kissed I know not how oft. Where be your gibes now? Your gambols? Your songs? Your flashes of merriment, that were wont to set the table on a roar?
It turns out that the E.Y. Davis was the playful alter ego of one of the Philadelphia Medical News editors, who wrote the piece after Parvin, another editor, wrote his report of treatment of vaginismus with a dilute cocaine solution because he wanted to make fun of Parvin, whom he considered a competitor.
So who was he? None other than Sir William Osler. Yes, Osler committed many cases of academic fraud using this pseudonym. His supporters call it all just good fun and use it to highlight his practical joker side, but it’s more than a practical joke when one uses his position of editorship to create fraudulent medical literature. The Philadelphia Medical News was not gomerblog.com. Osler apparently loved joking about it privately but never admitted that E.Y. Davis was fake. Consequently, a myth was perpetuated. Osler also committed other unmistakable acts of dishonesty and ethical depravity, like stealing the organs from a corpse when the family would not permit an autopsy.
I won’t spend time now discussing why penis captivus is almost certainly not a real clinical entity, though I will say that the vaginal muscles themselves could not physiologically stay so tensed for so long. If you are interested in more detailed commentary, here is an excellent resource. But there are a few lessons to be learned from this story.

{kind=link}
{kind=link}